
pwntools简单语法
作为最好用的pwn工具,简单记一下用法:
- 连接:本地process()、远程remote( , );对于remote函数可以接url并且指定端口
- 数据处理:主要是对整数进行打包:p32、p64是打包为二进制,u32、u64是解包为二进制
- IO模块:这个比较容易跟zio搞混,记住zio是read、write,pwn是recv、send
send(data): 发送数据
sendline(data) : 发送一行数据,相当于在末尾加n
recv(numb=4096, timeout=default) : 给出接收字节数,timeout指定超时
recvuntil(delims, drop=False) : 接收到delims的pattern
(以下可以看作until的特例)
recvline(keepends=True) : 接收到n,keepends指定保留n
recvall() : 接收到EOF
recvrepeat(timeout=default) : 接收到EOF或timeout
interactive() : 与shell交互
- ELF模块:获取基地址、获取函数地址(基于符号)、获取函数got地址、获取函数plt地址
e = ELF('/bin/cat')
print hex(e.address) # 文件装载的基地址
0x400000
print hex(e.symbols['write']) # 函数地址
0x401680
print hex(e.got['write']) # GOT表的地址
0x60b070
print hex(e.plt['write']) # PLT的地址
0x401680
- 解题常用:
context.arch = 'amd64' //设置架构
context.log_level = 'debug' //显示log详细信息
libc = ELF('./libc-2.24.so') //加载库文件
Pwn基础知识
ELF可重定位目标文件的节:
.bss(Block Strorage Start) 储存未初始化的全局和c变量,和被初始化为0的全局和静态变量
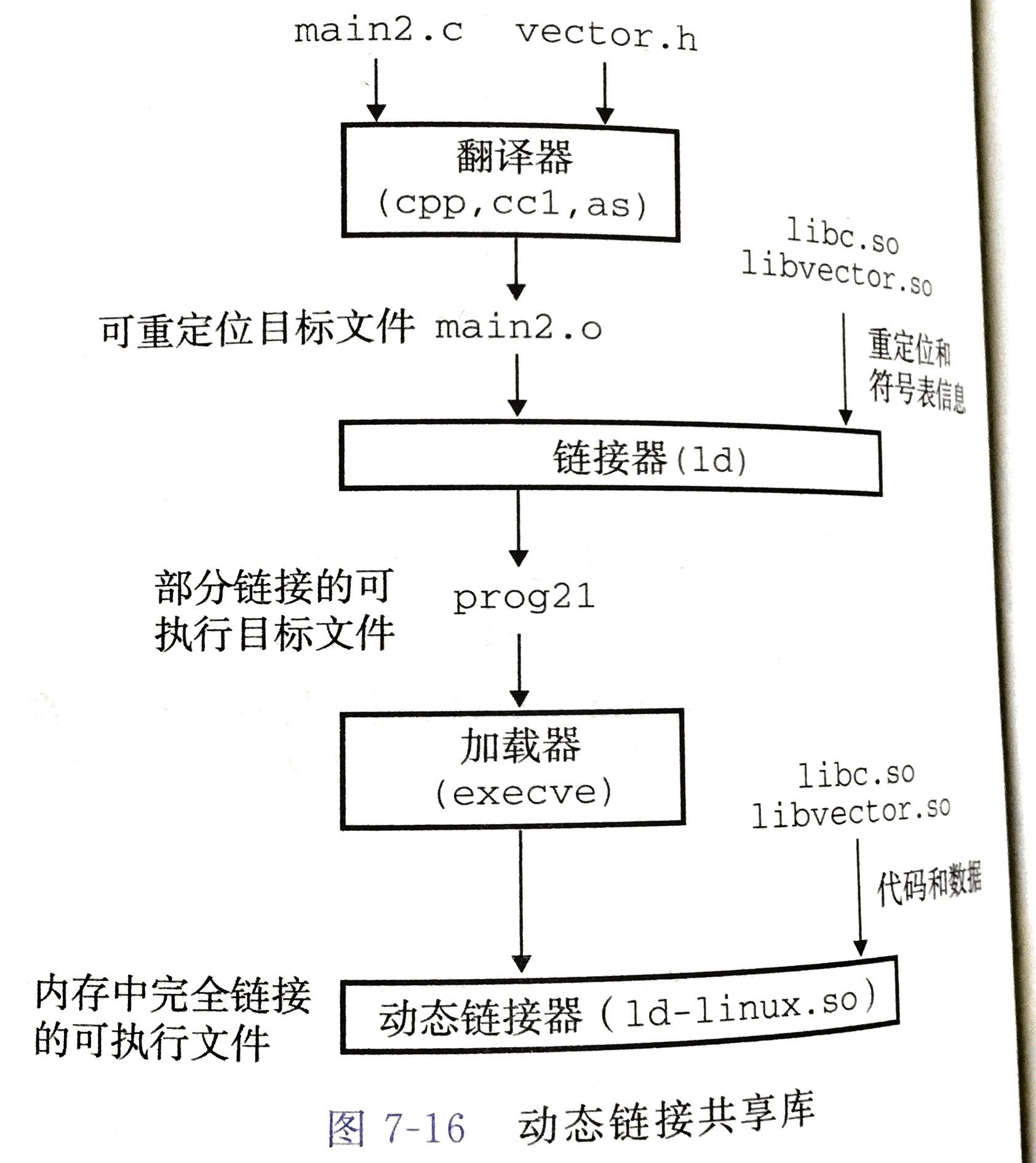
动态链接共享库
共享库是致力于解决静态库缺陷(定期维护和更新,重新链接)的一个产物,共享库也被称为共享目标(Shared Object),Linux中常用.so后缀来表示
动态链接过程如下:
位置无关代码(PIC)
共享库的一个主要目的是允许多个正在运行的进程共享内存中相同的库代码,节约内存资源。若是事先分配专用的地址空间片,要求加载器总是在这个地址加载,这样虽然简单,但对地址空间的使用效率不高,即使不用也要分配。除此之外难以管理,必须保证没有片会重叠,并且当库修改了之后必须确认已分配的片还适合它的大小,而修改之后更加难以管理,为了避免这些问题,现代操作系统引入了位置无关代码PIC(Position-Independent Code),使得可以把它们加载到内存的任何位置而无需链接器修改。
- PIC数据引用
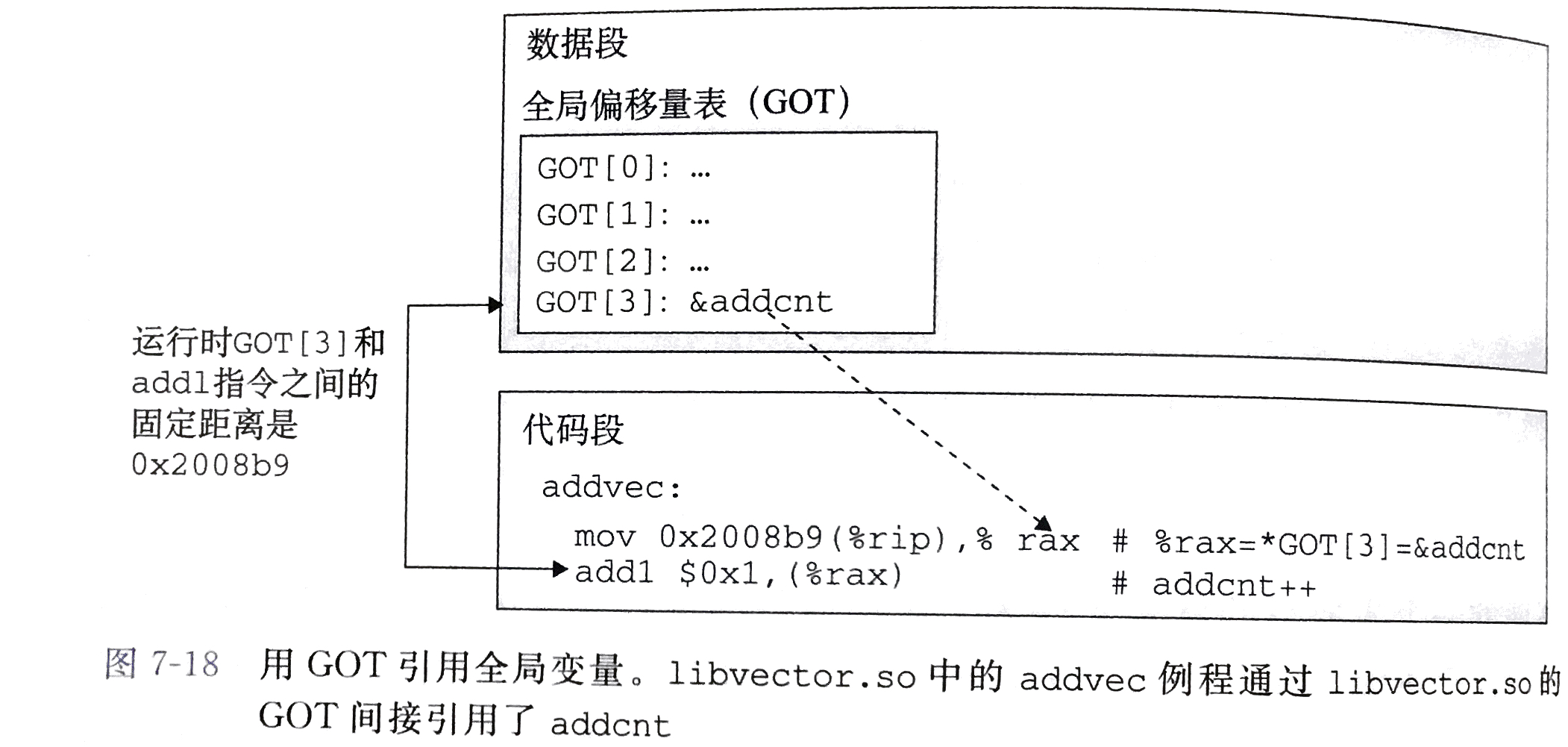
无论在内存的何处加载一个目标模块(包括共享目标模块),数据段与代码段的距离总保持不变,因此,代码段中任何指令和数据段中任何变量之间的距离都是一个运行时常量,与代码段和数据段的绝对内存位置无关。
编译器利用这个事实生成对全局变量PIC的引用,它在数据段开始的地方创建了一个表,叫做全局偏移量表(Global Offset Table,GOT)。在GOT中,每个被当前目标模块引用的全局数据(过程或全局变量)都有一个8字节条目(编译器还会为GOT表中每个条目生成一个重定位记录),加载时动态链接器重定位GOT中每个条目,使得它们包含目标的正确绝对地址。引用全局目标的目标模块都有自己的GOT
libvector.so共享模块的GOT,实现addcnt在内存中+1
- PIC函数调用(重点)
在ELF文件的动态连接机制中,每一个外部定义的符号在全局偏移表 (Global Offset Table,GOT)中有相应的条目,如果符号是函数则在过程连接表(Procedure Linkage Table,PLT)中也有相应的条目,且一个PLT条目对应一个GOT条目,原理如下:
假设程序调用一个由共享库定义的函数。编译器没有办法预测这个函数的运行时地址,因为定义它的共享模块在运行时可以加载到任意位置。正常的方法是为该引用生成一条重定位记录,然后动态链接器在程序加载的时候再解析它。不过,因为它需要链接器修改调用模块的代码段,GUN使用延迟绑定(lazy binding)将过程地址的绑定推迟到第一次调用该过程时。
使用延迟绑定的动机是对于一个像libc.so这样的共享库输出的成百上千个函数中,一个典型的应用程序只会使用其中很少的一部分,把函数地址的解析推迟到它实际被调用的地方,能避免动态链接器在加载时进行成百上千个其实并不需要的重定位。第一次调用过程的运行时开销很大,但是其后的每次调用都只会花费一条指令和一个间接的内存引用。
延迟绑定是通过两个数据结构【GOT和过程链接表(Procedure Linkage Table,PLT)】之间的交互实现,如果一个目标模块调用定义在共享库的任何函数,那么它就有GOT和PLT,GOT是数据段的一部分,PLT是代码段的一部分

如图,
PLT是一个数组,其中每个条目是16字节代码。PLT[0]是个特殊条目,它跳转到动态链接器中。每个被可执行程序调用的库函数都有它自己的PLT条目。每个条目都负责调用一个具体的函数。PLT[1]调用系统启动函数(__libc_start_main),它初始化执行环境,调用main 函数并处理其返回值。从PLT[2]开始的条目调用用户代码调用的函数,PLT[2]调用addvec,PLT[3]调用printf。
全局偏移量表(GOT)是一个数组,其中每个条目是8字节地址。和PLT联合使用时,GOT[O]和GOT[1]包含动态链接器在解析函数地址时会使用的信息。GOT[2]是动态链接器在ld-linux.so模块中的人口点。其余的每个条目对应于一个被调用的函数,其地址需要在运行时被解析。每个条目都有一个相匹配的PLT条目。例如,GOT[4]和PLT[2]对应于addvec。初始时,每个GOT条目都指向对应PLT条目的第二条指令。
图中步骤:
第1步:不直接调用addvec,程序调用进入PLT[2],这是addvec的PLT条目。
第2步:第一条PLT指令通过GOT[4]进行间接跳转。因为每个GOT条目初始时都指向它对应的PLT条目的第二条指令,这个间接跳转只是简单地把控制传送回PLT[2]中的下一条指令。
第3步:在把addvec 的ID(0x1)压人栈中之后,PLT[2]跳转到PLT[0]。
第4步:PLT[0]通过GOT[1]间接地把动态链接器的一个参数压人栈中,然后通过GOT[2]间接跳转进动态链接器中。动态链接器使用两个栈条目来确定addvec的运行时位置,用这个地址重写GOT[4],再把控制传递给addvec。
图7-19b是后续再调用addvec时的控制流:
第1步:和前面一样,控制传递到PLT[2]。
第2步:不过这次通过GOT[4]的间接跳转会将控制直接转移到addvec
脚本检测与各类防护技术
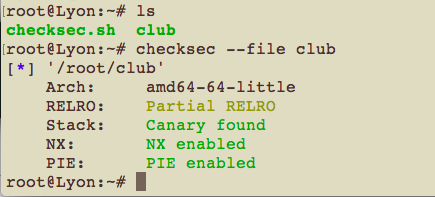
首先使用checksec,
防护技术:
RELRO:在Linux系统安全领域数据可以写的存储区就会是攻击的目标,尤其是存储函数指针的区域,尽量减少可写的存储区域可使安全系数提高。GCC, GNU linker以及Glibc-dynamic linker一起配合实现了一种叫做relro的技术Relocation Read Only, 重定向只读,实现就是由linker指定binary的一块经过dynamic linker处理过 relocation之后的区域为只读。(参考RELRO技术细节)
Stack: 栈溢出检查,用Canary金丝雀值是否变化来检测,Canary found表示开启。
金丝雀最早指的是矿工曾利用金丝雀来确认是否有气体泄漏,如果金丝雀因为气体泄漏而中毒死亡,可以给矿工预警。这里是一种缓冲区溢出攻击缓解手段:启用栈保护后,函数开始执行的时候会先往栈里插入cookie信息,当函数真正返回的时候会验证cookie信息是否合法,如果不合法就停止程序运行。攻击者在覆盖返回地址的时候往往也会将cookie信息给覆盖掉,导致栈保护检查失败而阻止shellcode的执行。在Linux将cookie信息称为Canary。
NX: No Execute,栈不可执行,也就是windows上的DEP。
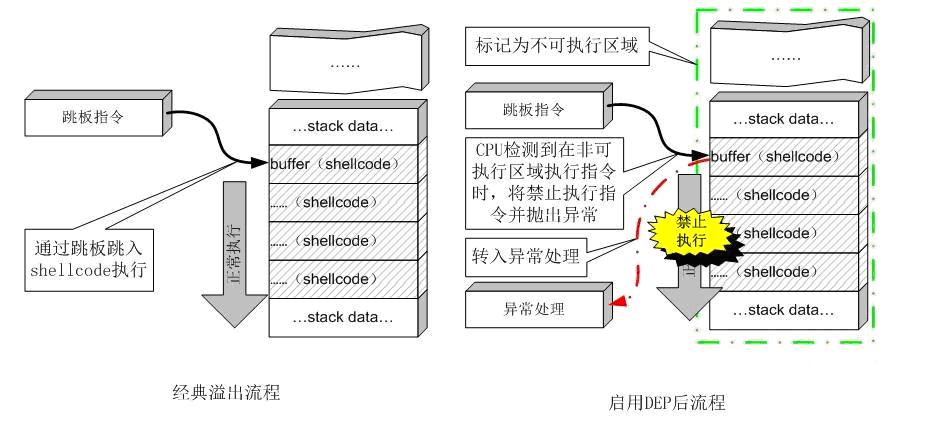
分析缓冲区溢出攻击,其根源在于现代计算机对数据和代码没有明确区分这一先天缺陷,就目前来看重新去设计计算机体系结构基本上是不可能的,我们只能靠向前兼容的修补来减少溢出带来的损害,DEP就是用来弥补计算机对数据和代码混淆这一天然缺陷的。
DEP的基本原理是将数据所在内存页标识为不可执行,当程序溢出成功转入shellcode时,程序会尝试在数据页面上执行指令,此时CPU就会抛出异常,而不是去执行恶意指令。DEP的主要作用是阻止数据页(如默认的堆页、各种堆栈页以及内存池页)执行代码。硬件DEP需要CPU的支持,AMD和Intel都为此做了设计,AMD称之为No-Execute Page-Protection(NX),Intel称之为Execute Disable Bit(XD)
Linux称为 NX 与 DEP原理相同
PIE: position-independent executables, 位置无关的可执行文件,也就是常说的ASLR(Address space layout randomization) 地址随机化,程序每次启动基址都随机。
Linux虚拟内存系统与动态内存的分配
12.01
Linux使用内存分配器 ptmalloc2 – glibc
glibc是GNU发布的libc库,即c运行库。glibc是linux系统中最底层的api,几乎其它任何运行库都会依赖于glibc。glibc除了封装linux操作系统所提供的系统服务外,它本身也提供了许多其它一些必要功能服务的实现。
Linux进程的虚拟内存
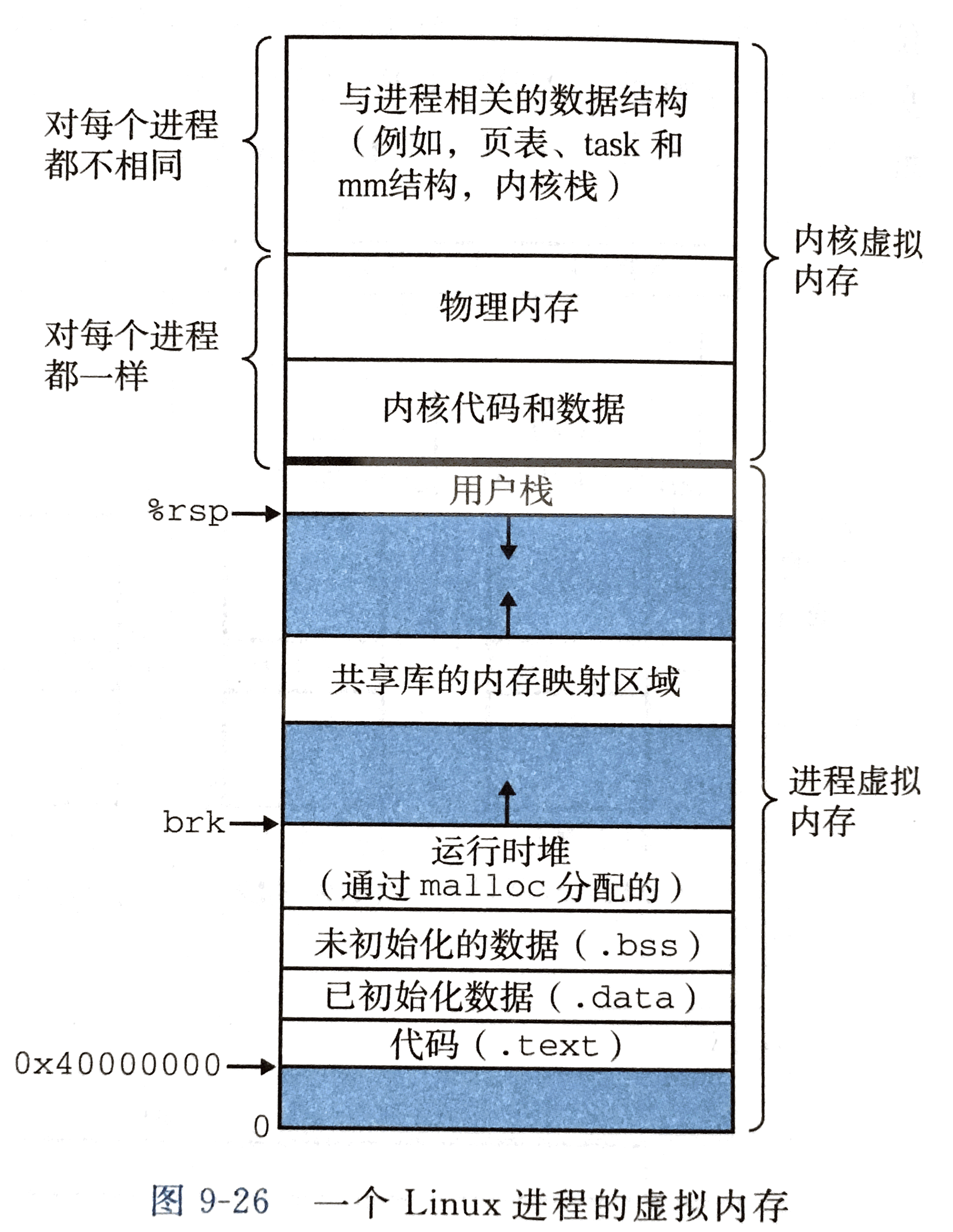
Linux为每个进程维护了一个单独的虚拟地址空间,形式如图所示。内核虚拟内存包含内核中的代码和数据结构。内核虚拟内存的某些区域被映射到所有进程共享的物理页面。每个进程共享内核的代码和全局数据结构。Linux将虚拟内存组织成一些区域(也叫做段)的集合。一个区域(area 就已经存在着的(已分配的)虚拟内存的连续片(chunk),这些页是以某种方式相关联的。例如,代码段、数据段、堆、共享库段,以及用户栈都是不同的区域。每个存在的虚拟页面都保存在某个区域中,而不属于某个区域的虚拟页是不存在的,并且不能被进程引用。区域允许虚拟地址空间有间隙。内核不用记录那些不存在的虚报页,而这样的页也不占用内存、磁盘或者内核本身中的任何额外资源。
系统内存分布图:
函数调用关系图:
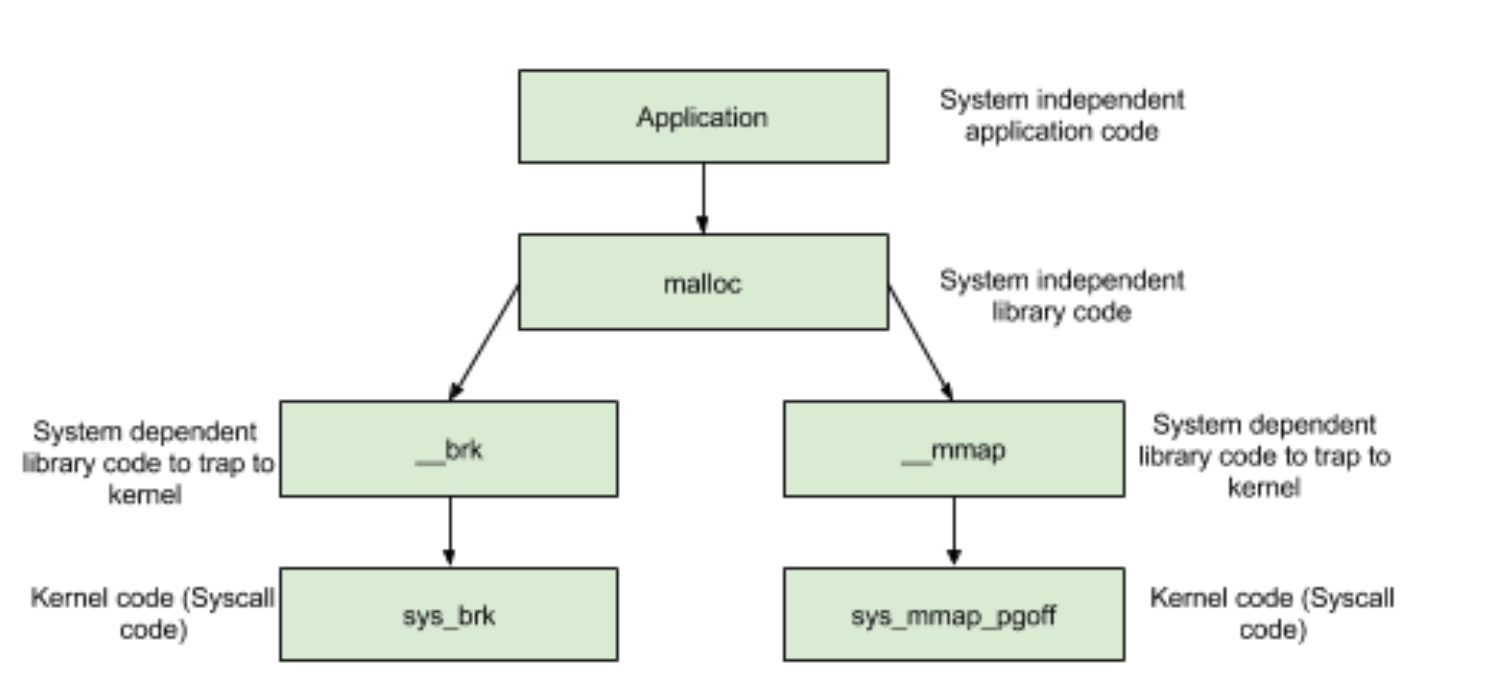
Linux进程分配的方式: _brk()和_mmap()
如上图,从操作系统角度来看,进程分配内存有两种方式,分别由两个系统调用完成:brk和mmap(不考虑共享内存)
- brk是将数据段(.data)的最高地址指针_edata往高地址推;
- mmap是在进程的虚拟地址空间中(堆和栈中间,称为文件映射区域的地方)找一块空闲的虚拟内存。
这两种方式分配的是虚拟内存,没有分配物理内存。在第一次访问已分配的虚拟地址空间时,发生缺页中断,操作系统负责分配物理内存,然后建立虚拟内存和物理内存之间的映射关系
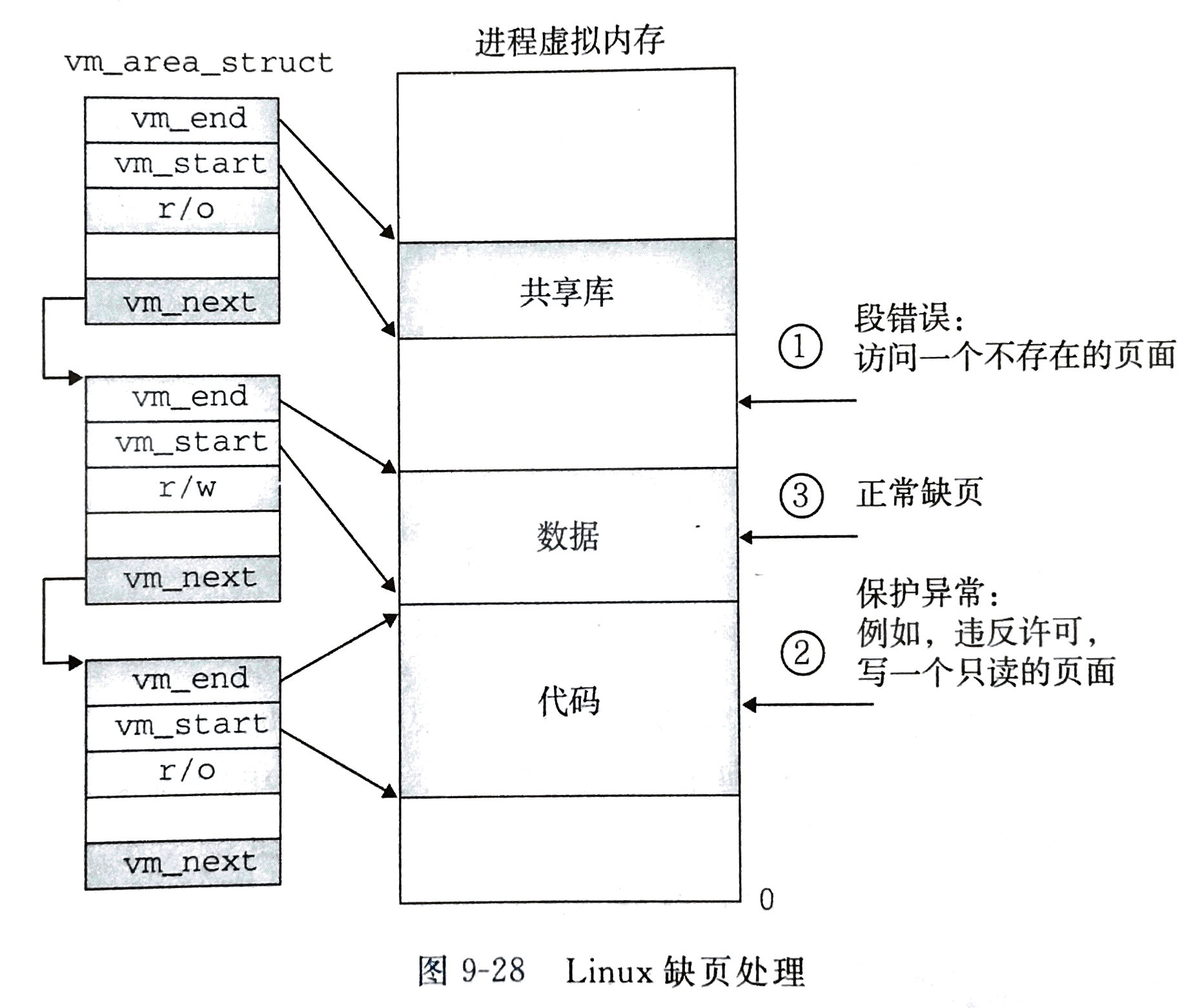
关于进程缺页中断:当MMU试图翻译某个虚拟地址时,
ps -o majflt/minflt -C program //查看进程发生缺页中断的次数
majflt代表major fault,中文叫大错误,minflt代表minor fault,中文叫小错误
当一个进程发生缺页中断的时候,进程会陷入内核态,执行以下操作:
- 检查要访问的虚拟地址是否合法(是否在定义区域内),检查试图进行的内存访问是否合法(进程是否有这段内存的权限)
- 查找/分配一个物理页
- 填充物理页内容(读取磁盘,或者直接置0,或者什么也不干)
- 建立映射关系(虚拟地址到物理地址)
重新执行发生缺页中断的那条指令,如果第3步,需要读取磁盘,那么这次缺页中断就是majflt,否则就是minflt
在标准C库中,提供了malloc/free函数分配释放内存,这两个函数底层是由brk,mmap,munmap这些系统调用实现的
动态内存分配:
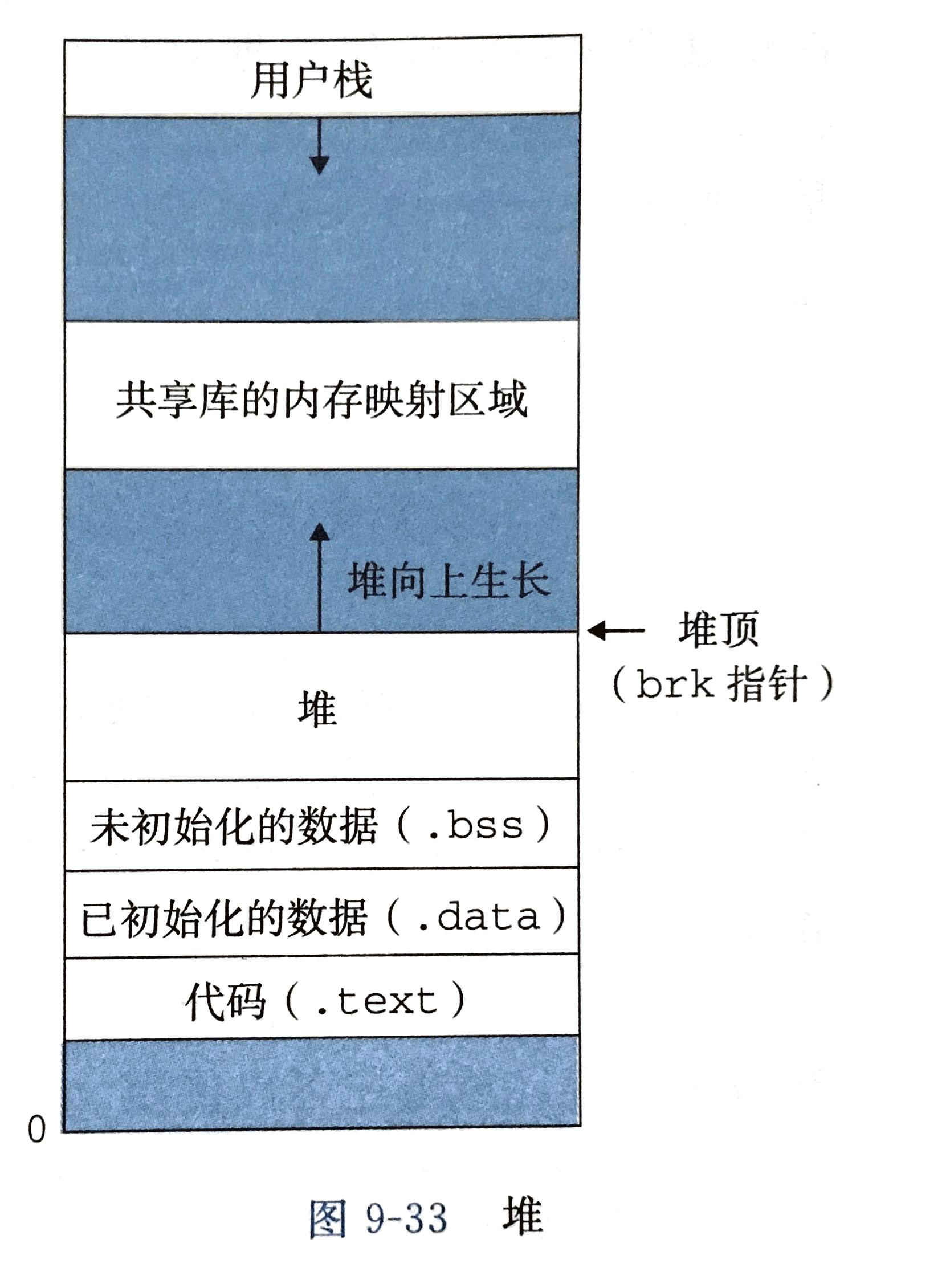
需要额外虚拟内存时,用动态内存分配器(dynamic memory allocator)更方便,也有更好的可移植性。
动态内存分配器维护着一个进程的虚拟内存区域,称为堆(heap)。系统之间细节不同,但是不失通用性,假设堆是一个请求二进制零的区域,它紧接在未初始化的数据区域后开始,并向上生长(向更高的地址)。对于每个进程,内核维护着一个变量brk(“break"),它指向堆的顶部。分配器将堆视为一组不同大小的块(block)的集合来维护。每个块就是一个连续的虚拟内存片(chunk),要么是已分配的,要么是空闲的。已分配的块显式地保留为供应用程序使用。空闲块可用来分配。空闲块保持空闲,直到它显式地被应用所分配。一个已分配的块保持已分配状态,直到它被释放,这种释放要么是应用程序显式执行的,要么是内存分配器自身隐式执行的。
分配器有两种基本风格(显式分配器,如c malloc free;隐式分配器,如java)。两种风格都要求应用显式地分配块。它们的不同之处在于由哪个实体来负责释放已分配的块。
举例说明:
- malloc小于128k的内存,使用brk分配内存,将_edata往高地址推(只分配虚拟空间,不对应物理内存(因此没有初始化),第一次读/写数据时,引起内核缺页中断,内核才分配对应的物理内存,然后虚拟地址空间建立映射关系),如下图:
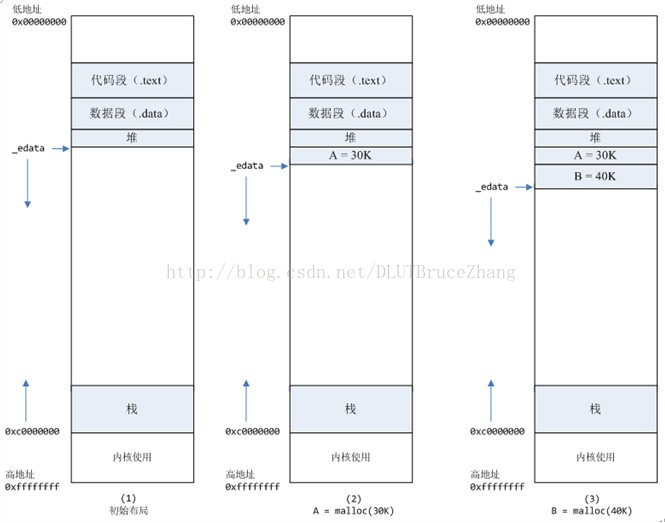
- malloc大于128k的内存,使用mmap分配内存,在堆和栈之间找一块空闲内存分配(对应独立内存,而且初始化为0),如下图:
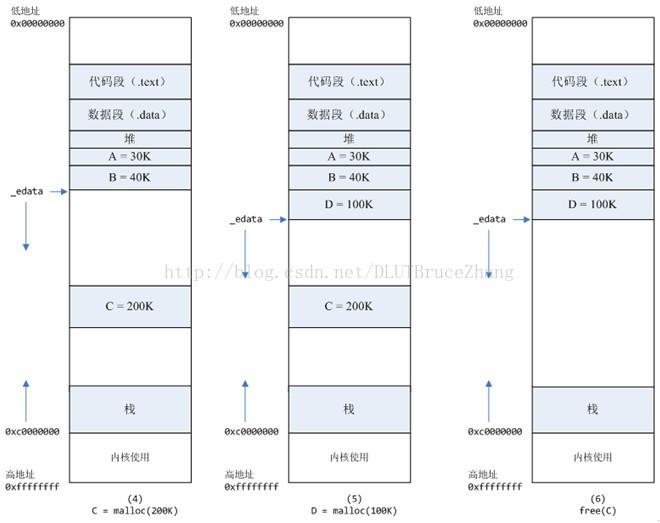
- 进程调用free(B)以后,如图7所示:B对应的虚拟内存和物理内存都没有释放,因为只有一个_edata指针,如果往回推,那么D这块内存怎么处理?当然,B这块内存,是可以重用的,如果这个时候再来一个40K的请求,那么malloc很可能就把B这块内存返回
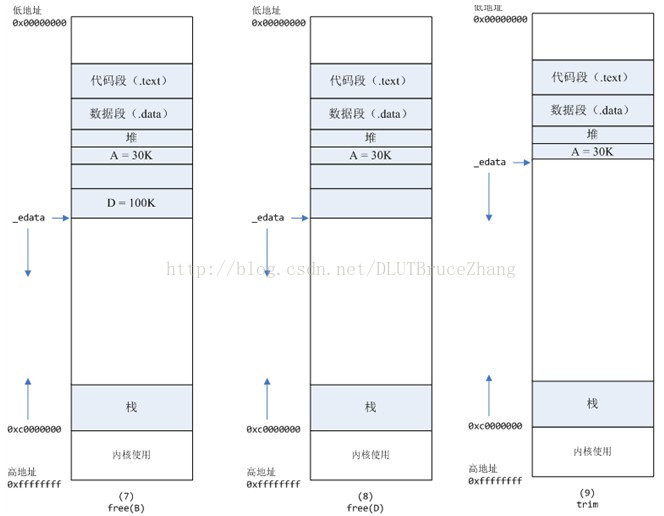
- 进程调用free(D)以后,如图8所示:
当最高地址空间的空闲内存超过128K(可由M_TRIM_THRESHOLD选项调节)时,执行内存紧缩操作(trim)。在上一个步骤free的时候,发现最高地址空闲内存超过128K,于是内存紧缩,变成图9所示。
Linux堆溢出漏洞利用之unlink
关于chunk: malloc文档
eglibc-2.19/malloc/malloc.c:1094
/*
----------------------- Chunk representations -----------------------
*/
/*
This struct declaration is misleading (but accurate and necessary).
It declares a "view" into memory allowing access to necessary
fields at known offsets from a given base. See explanation below.
*/
// 一个 chunk 的完整结构体
struct malloc_chunk {
INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */
INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */
struct malloc_chunk* fd; /* double links -- used only if free. */
struct malloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */
struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
struct malloc_chunk* bk_nextsize;
};
/*
malloc_chunk details:
(The following includes lightly edited explanations by Colin Plumb.)
// chunk 的内存管理采用边界标识的方法, 空闲 chunk 的 size 在该 chunk 的 size 字段和下一个 chunk 的 pre_size 字段都有记录
Chunks of memory are maintained using a `boundary tag' method as
described in e.g., Knuth or Standish. (See the paper by Paul
Wilson ftp://ftp.cs.utexas.edu/pub/garbage/allocsrv.ps for a
survey of such techniques.) Sizes of free chunks are stored both
in the front of each chunk and at the end. This makes
consolidating fragmented chunks into bigger chunks very fast. The
size fields also hold bits representing whether chunks are free or
in use.
An allocated chunk looks like this:
// 正在使用的 chunk 布局
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of previous chunk, if allocated | |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of chunk, in bytes |M|P|
mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| User data starts here... .
. .
. (malloc_usable_size() bytes) .
. |
nextchunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of chunk |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
// 几个术语规定, 'chunk' 就是整个 chunk 开头, 'mem' 就是用户数据的开始, 'Nextchunk' 就是下一个 chunk 的开头
Where "chunk" is the front of the chunk for the purpose of most of
the malloc code, but "mem" is the pointer that is returned to the
user. "Nextchunk" is the beginning of the next contiguous chunk.
// chunk 是双字长对齐
Chunks always begin on even word boundaries, so the mem portion
(which is returned to the user) is also on an even word boundary, and
thus at least double-word aligned.
// 空闲 chunk 被存放在双向环链表
Free chunks are stored in circular doubly-linked lists, and look like this:
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of previous chunk |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
`head:' | Size of chunk, in bytes |P|
mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Forward pointer to next chunk in list |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Back pointer to previous chunk in list |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Unused space (may be 0 bytes long) .
. .
. |
nextchunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
`foot:' | Size of chunk, in bytes |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
// P 标志位不能放在 size 字段的低位字节, 用于表示前一个 chunk 是否在被使用, 如果为 0, 表示前一个 chunk 空闲, 同时 pre_size 也表示前一个空闲 chunk 的大小, 可以用于找到前一个 chunk 的地址, 方便合并空闲 chunk, 但 chunk 刚一开始分配时默认 P 为 1. 如果 P 标志位被设置, 也就无法获取到前一个 chunk 的 size, 也就拿不到前一个 chunk 地址, 也就无法修改正在使用的 chunk, 但是这是无法修改前一个 chunk, 但是可以通过本 chunk 的 size 获得下一个 chunk 的地址.
The P (PREV_INUSE) bit, stored in the unused low-order bit of the
chunk size (which is always a multiple of two words), is an in-use
bit for the *previous* chunk. If that bit is *clear*, then the
word before the current chunk size contains the previous chunk
size, and can be used to find the front of the previous chunk.
The very first chunk allocated always has this bit set,
preventing access to non-existent (or non-owned) memory. If
prev_inuse is set for any given chunk, then you CANNOT determine
the size of the previous chunk, and might even get a memory
addressing fault when trying to do so.
Note that the `foot' of the current chunk is actually represented
as the prev_size of the NEXT chunk. This makes it easier to
deal with alignments etc but can be very confusing when trying
to extend or adapt this code.
The two exceptions to all this are
// 这里的 the trailing size 是指下一个 chunk 的 pre_size, 因为 top 位于最高地址, 不存在相邻的下一个 chunk, 同时这里也解答了上面关于 top 什么时候重新填满
1. The special chunk `top' doesn't bother using the
trailing size field since there is no next contiguous chunk
that would have to index off it. After initialization, `top'
is forced to always exist. If it would become less than
MINSIZE bytes long, it is replenished.
2. Chunks allocated via mmap, which have the second-lowest-order
bit M (IS_MMAPPED) set in their size fields. Because they are
allocated one-by-one, each must contain its own trailing size field.
*/
P(PREV_INUSE)标志位表示前一个 chunk 是否在使用, 0 为没有在使用.
prev_size 表示前一个 chunk 的大小, 仅在 P (PREV_INUSE) 为 0 时有效, 也就是前一个 chunk 为空闲状态.
size 表示该整个 chunk 大小, 并非 malloc 返回值.
fd, bk, fd_nextsize, fd_nextsize 是对于空闲 chunk 而言, 对于正在使用的 chunk, 从当前位置开始就是 malloc 返回给用户可用的空间.
fd, bk 组成了 Bins 的双向环链表
对于空闲的 chunk 空间布局, 见上, 是环形双向链表. 存放在空闲 chunk 容器中.
关于 chunk 有一些操作, 判断前一个是否在使用, 判断下一个 chunk 是否正在使用, 是不是 mmap 分配的, 以及对标志位 P 等的操作, 可以参考 glibc/malloc/malloc.c:1206 中 Physical chunk operations 一小节
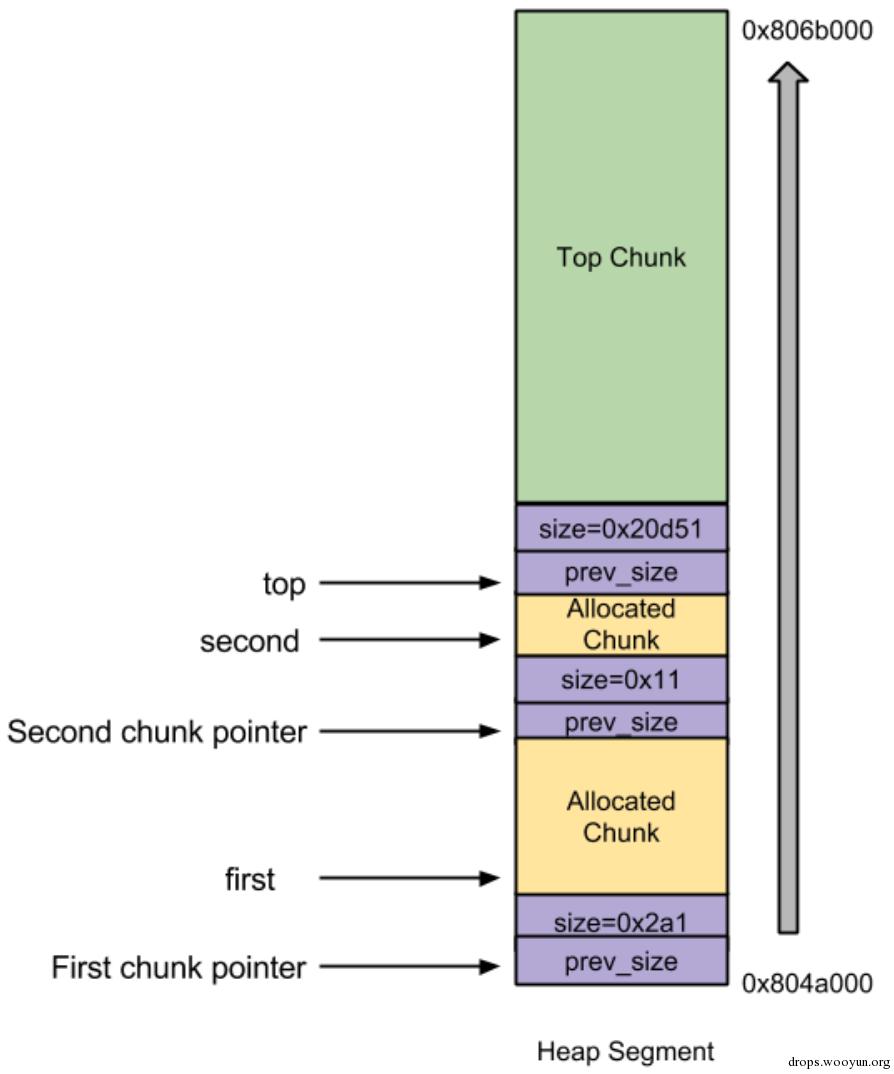
如图,如果输入值的大小比first变量的字节更大,那么输入的数据就有可能覆盖掉下一个chunk的chunk header——这可以导致任意代码执行
基本知识介绍:
unlink攻击技术就是利用glibc malloc的内存回收机制,欺骗glibc malloc 来 unlink 第二个块。unlink free的 GOT 条目会使其被 shellcode 地址覆盖。free被漏洞程序调用时,shellcode 就会执行。
显然,核心就是glibc malloc的free机制
一旦涉及到free内存,那么就意味着有新的chunk由allocated状态变成了free状态,此时glibc malloc就需要进行合并操作——向前以及(或)向后合并。这里所谓向前向后的概念如下:将previous free chunk合并到当前free chunk,叫做向后合并;将后面的free chunk合并到当前free chunk,叫做向前合并
/*malloc.c int_free函数中*/
/*这里p指向当前malloc_chunk结构体,bck和fwd分别为当前chunk的向后和向前一个free chunk*/
/* consolidate backward */
if (!prev_inuse(p)) {
prevsize = p->prev_size;
size += prevsize;
//修改指向当前chunk的指针,指向前一个chunk。
p = chunk_at_offset(p, -((long) prevsize));
unlink(p, bck, fwd);
}
//相关函数说明:
/* Treat space at ptr + offset as a chunk */
#define chunk_at_offset(p, s) ((mchunkptr) (((char *) (p)) + (s)))
/*unlink操作的实质就是:将P所指向的chunk从双向链表中移除,这里BK与FD用作临时变量*/
#define unlink(P, BK, FD) {
FD = P->fd;
BK = P->bk;
FD->bk = BK;
BK->fd = FD;
...
}
整理一下:
首先检测前一个chunk是否为free,这可以通过检测当前free chunk的PREV_INUSE(P)比特位知晓。当前chunk(first chunk)的前一个chunk是allocated的,因为在默认情况下,堆内存中的第一个chunk总是被设置为allocated的,即使它根本就不存在。
如果为free的话,那么就进行向后合并:
1)将前一个chunk占用的内存合并到当前chunk;
2)修改指向当前chunk的指针,改为指向前一个chunk。
3)使用unlink宏,将前一个free chunk从双向循环链表中移除
向前合并:
……
/*这里p指向当前chunk*/
nextchunk = chunk_at_offset(p, size);
……
nextsize = chunksize(nextchunk);
……
if (nextchunk != av->top) {
/* get and clear inuse bit */
nextinuse = inuse_bit_at_offset(nextchunk, nextsize); //判断nextchunk是否为free chunk
/* consolidate forward */
if (!nextinuse) { //next chunk为free chunk
unlink(nextchunk, bck, fwd); //将nextchunk从链表中移除
size += nextsize; // p还是指向当前chunk只是当前chunk的size扩大了,这就是向前合并!
} else
clear_inuse_bit_at_offset(nextchunk, 0);
……
}
对抗技术:
glibc malloc对相应的安全机制进行了加强,具体而言,就是添加了如下几条安全检测机制。
- Double Free检测
该机制不允许释放一个已经处于free状态的chunk。因此,当攻击者将second chunk的size设置为-4的时候,就意味着该size的PREV_INUSE位为0,也就是说second chunk之前的first chunk(我们需要free的chunk)已经处于free状态,那么这时候再free(first)的话,就会报出double free错误。相关代码如下:
/* Or whether the block is actually not marked used. */
if (__glibc_unlikely (!prev_inuse(nextchunk)))
{
errstr = "double free or corruption (!prev)";
goto errout;
}
- next size非法检测
该机制检测next size是否在8到当前arena的整个系统内存大小之间。因此当检测到next size为-4的时候,就会报出invalid next size错误。相关代码如下:
nextsize = chunksize(nextchunk);
if (__builtin_expect (nextchunk->size = av->system_mem, 0)){
errstr = "free(): invalid next size (normal)";
goto errout;
}
- 双链表冲突检测
该机制会在执行unlink操作的时候检测链表中前一个chunk的fd与后一个chunk的bk是否都指向当前需要unlink的chunk。这样攻击者就无法替换second chunk的fd与fd了。相关代码如下:
if (__builtin_expect (FD->bk != P || BK->fd != P, 0)) malloc_printerr (check_action, "corrupted double-linked list", P);
以上-----------------------------
Hits: 309





