
我们这节开始讲解HTTP协议和BurpSuite工具的使用
开始之前呢,我们先预告一下<实战课程>
按照我们的课程大纲,我们将于<4/29>开始我们的第一个实战课程
所以分期购买靶机的同学可以在<4/23>到<4/28>这段时间里开始购买了
然后私信给我,我拉你进群~
由于前6期的课程内容主要是理论为主,所以第一期实战的内容也不会太难~
只要你用心做~
都是可以做出来滴~
今天的文章有点长~

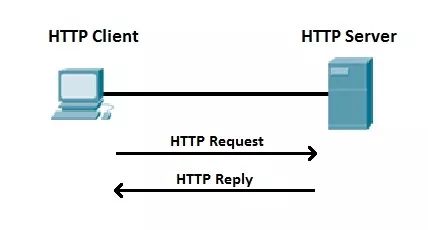
HTTP(Hypertext Transfer Protocol)中文<超文本传输协议>,是一种为分布式,合作式,多媒体信息系统服务,面向应用层的协议,是Internet上目前使用最广泛的应用层协议
它基于传输层的TCP协议进行通信,HTTP协议是通用的、无状态的协议,主要用于在服务器和客户机之间传输超文本文件

从1990年就已经用来作为www的传输协议,当时非常简单,只支持GET方法,响应中携带的消息必须HTML文件
1996发布RFC1945,90年代后期,基于0.9的各种客户端和服务端的扩展层出不穷,把这些扩展进行综合推出新标准HTTP/1.0
1997推出RFC2068,HTTP/1.1的标准
1999推出RFC2616,废弃了RFC2068标准
2015作为互联网标准正式发布
注意一点:HTTP是比TCP高级的传输协议~
建立HTTP连接的步骤:

2. 客户端向服务器端发送请求
3. 服务器端向客户端回复响应
4. 断开连接

HTTP/1.1协议中共定义了八种方法(也叫<动作>)来以不同方式操作指定的资源
向指定的资源发出<显示>请求,使用GET方法应该只用在读取数据,而不应当被用于产生<副作用>的操作中,其中一个原因是,例如在一个Web Application中,GET可能会被网络蜘蛛等随意访问
与GET方法一样,都是向服务器发出指定资源的请求,只不过服务器将不传回资源的本文部分
它的好处在于,使用这个方法可以在不必传输全部内容的情况下,就可以获取其中<关于该资源的信息>(元信息或称元数据)
向指定资源提交数据,请求服务器进行处理(例如提交表单或者上传文件)
数据被包含在请求本文中。这个请求可能会创建新的资源或修改现有资源,或二者皆有
向指定资源位置上传其最新内容
请求服务器删除Request-URI所标识的资源
回显服务器收到的请求,主要用于测试或诊断
这个方法可使服务器传回该资源所支持的所有HTTP请求方法,用'*'来代替资源名称,向Web服务器发送OPTIONS请求,可以测试服务器功能是否正常运作
HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。通常用于SSL加密服务器的链接(经由非加密的HTTP代理服务器)
HTTP服务器至少应该实现GET和HEAD方法,其他方法都是可选的,当然,所有的方法支持的实现都应当匹配下述的方法各自的语义定义。此外,除了上述方法,特定的HTTP服务器还能够扩展自定义的方法
例如:
PATCH(由 RFC 5789 指定的方法)
用于将局部修改应用到资源
主要分成两大类
Request由客户端发给服务器的消息。其组成包括
请求头(Request header fields)
空行(Empty Line)
消息体(Message Body)
其中
请求行和标题必须以<CR><LF>作为结尾,空行内必须只有<CR><LF>而无其他空格
在HTTP/1.1协议中,所有的请求头,除Host外,都是可选的
我们来看个请求的例子
GET / HTTP/1.1Host: www.google.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:59.0) Gecko/20100101 Firefox/59.0Accept: */*
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflateCache-Control: no-cachePragma: no-cacheConnection: close
第一行的GET是请求行
第二行的Host是1.1版里必带的一个header,用于指定主机
Response是服务端回复客户端请求的消息,其组成包括
响应头 (Response Header Field)
空行(Empty Line)
消息体(Message Body)
这里呢
状态行和其他标题字段必须全部以<CR><LF>结尾
空行必须只包含<CR><LF>,而不能包含其他空格
对<CR><LF>的这种严格要求在邮件正文中有所放宽,以便一致地使用其他系统断行,例如单独<CR>或<LF>
这里我们看一个例子,是上面那个请求的Response
HTTP/1.1 200 OK
Date: Mon, 23 May 2018 22:38:34 GMT
Content-Type: text/html; charset=UTF-8
Content-Encoding: UTF-8
Content-Length: 138
Last-Modified: Wed, 08 Jan 2018 23:11:55 GMT
Server: Apache/1.3.3.7 (Unix) (Red-Hat/Linux)
ETag: "3f80f-1b6-3e1cb03b"
Accept-Ranges: bytes
Connection: close
<html>
<head>
<title>An Example Page</title>
</head>
<body>
Hello World, this is a very simple HTML document.
</body>
</html>
所有HTTP Response的第一行都是状态行,然后依次是当前HTTP版本号
状态码由3位数字组成的,还有描述状态的短语,彼此由空格分隔
状态代码的第一个数字代表当前响应的类型:
1xx 消息 --- 请求已被服务器接收,继续处理
2xx 成功 --- 请求已成功被服务器接收、理解、并接受
3xx 重定向 --- 需要后续操作才能完成这一请求
4xx 请求错误 --- 请求含有词法错误或者无法被执行
5xx 服务器错误 --- 服务器在处理某个正确请求时发生错误
虽然<RFC 2616>中已经推荐了描述状态的短语,例如<200 OK>,<404 Not Found>,但是Web开发者仍然能够自行决定采用何种短语,用以显示本地化的状态描述或者自定义信息
现在我们稍微解释一下上面那个Request和Response的意思
这句话是在告知服务器本浏览器不想使用永久连接方式,其中,HTTP/1.0使用默认非永久连接,而HTTP/1.1默认使用永久连接
这句话是用来指定用户浏览器的类型,有时候我们要绕过一些服务器的浏览器限制,可以通过编辑这个段来实现
其中,gzip, deflate指出发送此请求的浏览器支持哪些压缩编码方式
这个段是指出客户浏览器支持的语言是中文或者台湾中文或者香港中文(zh-CN and zh-TW and zh-HK)
指出服务器创建并发送本响应消息的日期和时间
HTTP允许下面三种不同格式的日期/时间,但必须是格林尼治标准时间
这里的Apache/1.3.3.7 (Unix) (Red-Hat/Linux)指出本消息是由Apache服务器产生的,并且服务器版本为1.3.3.7
为什么漏扫可以查看目标站的服务器版本,就是通过这里
这个字段是指出对象本身的创建或最后修改日期或时间,这主要是为了方便你在第二次访问一个网站的时候,网站会使用以前的浏览器缓存,如果浏览器缓存超过了一个时间,就会重新更新网页内容,有些黑客可以通过修改这个字段来让浏览器做一些事情
OK,下面我们加入实操与理论的结合
这个工具呢有免费版的和付费版的,我们用免费的社区版就行啦~
工具的下载地址

在kali中已经自带了这个
windows的安装过程中注意要安装和配置JDK
这里稍微解释一下BurpSuite(以下就简称BS了)
它被设计成供动手测试人员用来支持测试过程, 只需付出一点努力,任何人都可以开始使用Burp Suite的核心功能来测试其应用程序的安全性
Burp Suite的一些更高级的功能将需要进一步的学习和经验才能掌握。 所有这些投资都是非常值得的
Burp Suite的用户驱动工作流程是迄今为止执行Web安全测试最有效的方式,并且将超越任何传统的点击式扫描器的功能
我们先看看这个软件的大概有哪些功能
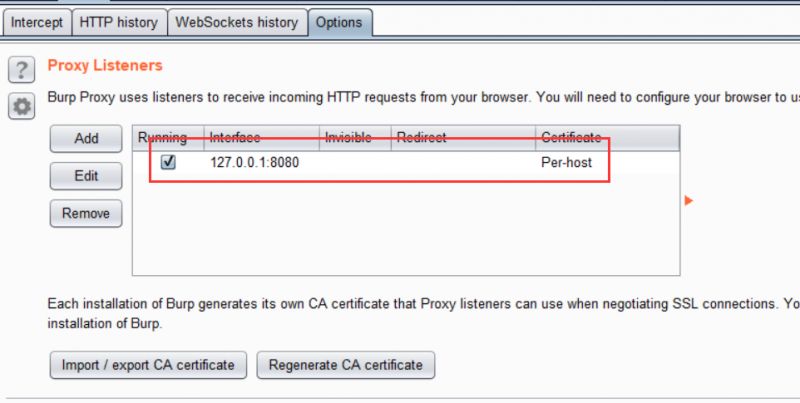
Burp Suite带有一个代理,通过默认端口8080上运行,使用这个代理,我们可以截获并修改从客户端到Web应用程序的数据包
Burp Suite的蜘蛛功能是用来抓取Web应用程序的链接和内容等,它会自动提交登陆表单(通过用户自定义输入)
Burp Suite的蜘蛛可以爬行扫描出网站上所有的链接,通过对这些链接的详细扫描来发现Web应用程序的漏洞 。
它是用来扫描Web应用程序漏洞的
在测试的过程中可能会出现一些误报,但是各位要记住,自动扫描器扫描的结果不可能完全100%准确.
这个单词的翻译是<入侵>,这个功能可用于多种用途,如漏洞的利用,Web应用程序模糊测试,进行暴力猜解等.
这个翻译过来呢就是<中继器>,此功能用于根据不同的情况修改和发送相同的请求次数并分析
也就是我们截获了一个流量包很重要,要对他进行分析和测试,就可以发送给Repeater来进行重复的测试了
此功能主要用来检查Web应用程序提供的会话令牌的随机性,并执行各种测试
翻译过来呢就是<解码>,此功能可用于解码数据找回原来的数据形式,或者进行编码和加密数据
一般用的比较多的还是解码,比如base64或者URL解码
此功能用来执行任意的两个请求,响应或任何其它形式的数据之间的比较
高级的功能我们就不一一介绍了,等用到的时候再说,现在我们先进行基础的配置,最起码先能用嘛
说这么多概念性的,休息一下
这里我们就直接跳过安装了,我们使用的浏览器优先选择火狐
首先我们打开社区版的BS

长这样的,后面
这里选择<Next>就行啦
点击<Start Burp>开始我们的旅程
整个界面长这样
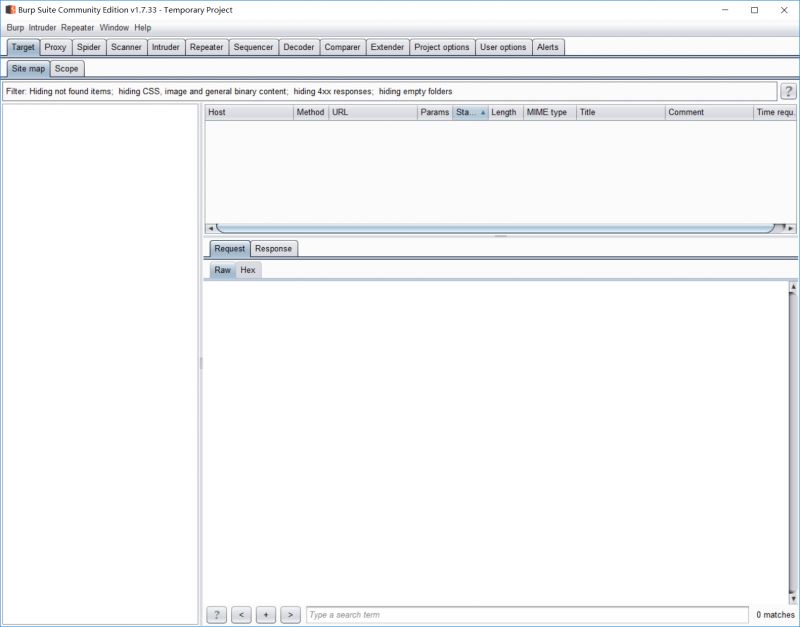
我们点开第二个<Proxy>
打开<Option>
在这里确保这个选项被勾上
当然,这里我有个习惯
默认的设置里面是只截Request的,但是我喜欢这里把Response也一起截了
下面的这个是截Request的
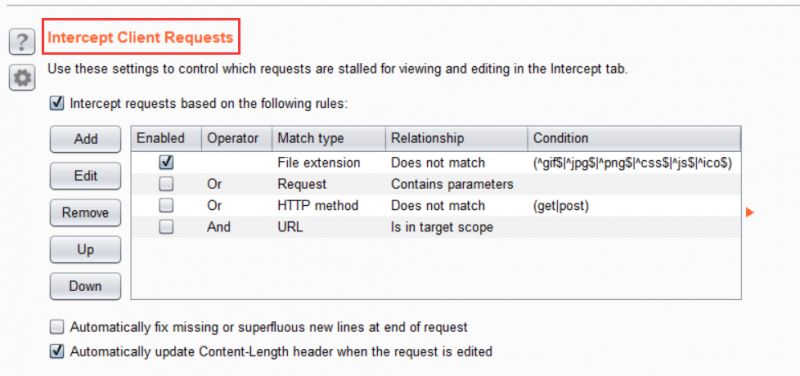
下面的这个是截Response的
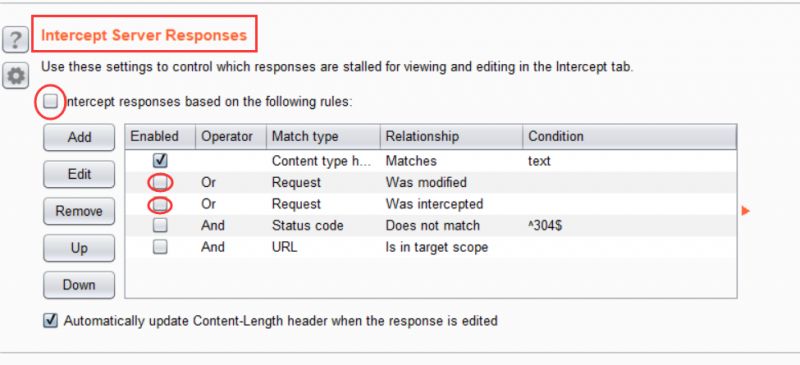
注意我圈出来的地方,这里打上勾就是截Response了
为啥要截Response呢,因为有时候网站会存在本地验证的漏洞,我们修改服务器返回的Response就可以看到一些我们不应该看到的东西~
设置好BS之后,我们打开火狐
点击<选项>
在最下面的这里选择<设置>(我这里是最新的火狐)
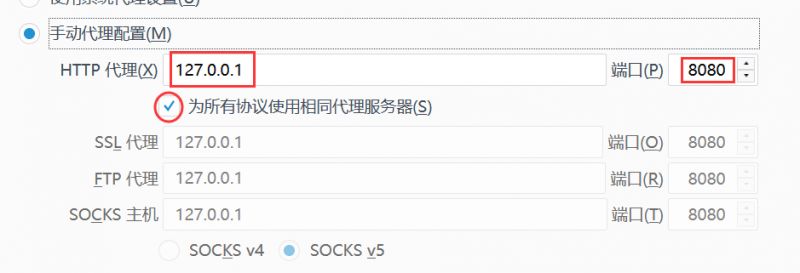
选择<手动代理配置>,之后填上我们的BS的地址和端口之后就可以了
这里是<127.0.0.1>和<8080>
然后我们就会看到BS里面已经有包过来了
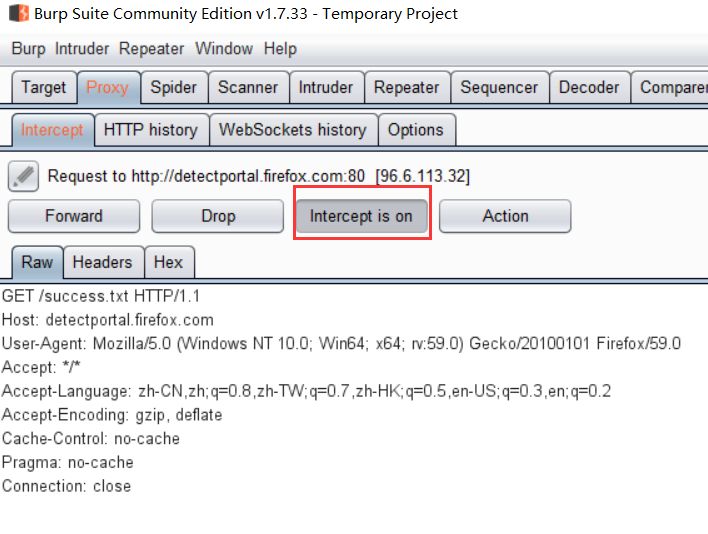
注意那个圈出来的,那个是开关
如果我们先重复这个流量包,我们点击旁边的<Action>
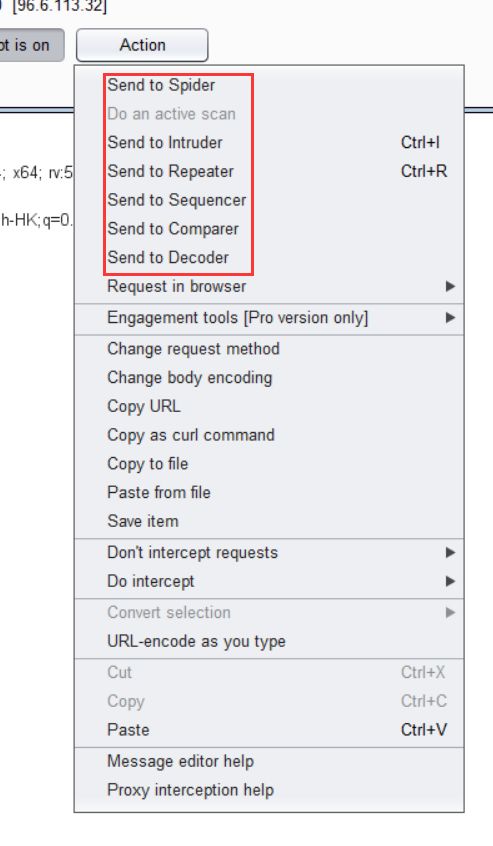
选择<Send to Repeater>就可以重复重复的发送这个包
这里还有一些<Send ...>的选项,以后用到我们再说
如果我们要解码一个base64编码,我们可以点这里
这里有三个我们用的比较多的的按钮
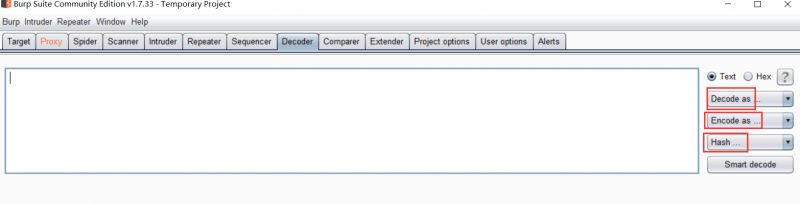
一个是
<Decode as ...>
这个是解码的意思
一个是
<Encode as ...>
这个是编码的意思
还有一个是
<Hash ...>
这个是计算Hash的意思
把要<解码/编码>的字符串放在上面的框框里面,点击<解码/编码>之后就可以在下面的框框里面得到结果
我们点击这个<Intruder>
这里的<Target>是目标的信息,<Positions>是攻击载荷在流量包中的位置,比如是在User字段呢还是在Passwd字段
<Payloads>是我们的字典的位置,或者你的攻击脚本的位置,我们可以在这里加载字典
<Options>是设置的地方
这里我们一般在CTF中用不到,但是对于渗透测试来说用处还是比较大的
>>> 下面的内容很重要:
>>> 该技术是面向有CTF比赛或者有合法授权的渗透测试,如若用户自己用于非法途径造成后果,与作者无关

本文完
下期内容:CTF实战5 Web漏洞辅助测试工具


本文来源于互联网:CTF实战4 HTTP协议及嗅探抓包
Hits: 174









